[Mathematical Statistics with Applications 7th Edition, Wackerly, Mendenhall, Scheaffer]
이산확률변수와 이산확률분포
3.1 Basic Definition
확률변수(random variable)
3.2 The Probability Distribution for a Discrete Random Variable
Example 3.1
공장에 3명의 남자와 3명의 여자 근로자가 있다. 감독관은 2명의 근로자를 뽑아 특별한 작업을 하려고 한다. 감독관은 random하게 2명의 근로자를 선택하려고 한다.
Solution
6명 중에서 2명을 뽑는 경우의 수는
여성이 0명인 경우
여성이 1명인 경우
여성이 2명인 경우
확률분포를 표, 히스토그램으로 나타내면 다음과 같다

그리고 공식으로 나타내면
풀이 끝
모든 이산 확률 분포(discrete probability distribution)에서 다음과 같은 성질을 만족한다
1)
2)
3.3 The Expected Value of a Random Variable or a Function of a Random Variable
확률변수
확률변수
의 기댓값은 다음과 같이 계산한다.
확률변수
Example 3.2
다음 표과 같이 확률변수
Solution
풀이 끝
확률변수
1)
2)
3)
그리고 확률변수
Example 3.3
공장 매니저는 2개의 새 타입(
각 경우가 비용의 기댓값이 작은 기계는?
(a) 10시간
(b) 20시간
Solution
분산 공식에서
풀이 끝
3.4 The Binomial Probability Distribution
이항 실행(binomial experiment)는 다음과 같은 성질을 갖는다
1) 각 실행은 고정된 수
2) 각 시행은 2개의 결과를 갖는다; 성공과 실패(
3) 각 시행마다 성공할 확률을 동일하다. 성공/실패할 확률을
4) 각 시행은 독립이다
5) 확률변수
확률변수
그리고
Example 3.10
20명의 설문조사를 통해 새로운 퇴직금 정책에 우호적인지 조사하였다. 우리의 표본에서 6명이 우호적이라 했을 때, 확률
Solution
양변에 로그를 합성하면
위 식이
(이 풀이 방법은 9장에서 최대우도법(maximum likelihood estimation)을 이용한 것이다)
풀이 끝
3.5 The Geometric Probability Distribution
기하분포를 따르는 확률변수는 이항분포와 몇가지 특징을 공유한다. 성공확률
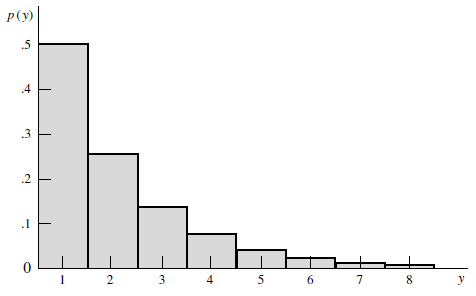
기하분포는 대기시간의 길이 분포에 자주 사용된다.
Example 3.11
엔진이 한시간동안 오작동할 확률이
Solution
풀이 끝.
기하분포의 평균과 분산은
Example 3.13
3.10번에서 한 인터뷰를 연속적으로 시행하고, 처음으로 긍정적으로 인터뷰한 사람에서 인터뷰를 멈추려고 한다. 만약 5번째 사람이 처음으로 긍적적으로 답한 사람이라면, p를 예측해보라.
Solution
풀이 끝.
3.6 The Negative Binomial Probability Distribution
음이항분포. 기하분포를 조금 확장하여
즉
Example 3.15
펌프 재고창고에서 20% 정도는 수리가 필요하다고 한다. 유지보수 근로자는 3개의 수리키트를 보내려고 한다. 근로자는 임의로 펌프를 고르고 한번에 테스트를 한다. 만약 펌프가 동작하면 나중에 사용하기 위해 따로 보관한다. 만약 펌프가 동작하지 않으면, 그녀는 수리키트를 사용한다.
정상펌프를 테스트하는데 10분이 걸리고, 고장난 펌프를 테스트하는데는 수리시간을 포함하여 30분이 걸린다고 하자. 3개의 수리키트를 사용하는데 소요되는 시간의 평균과 분산을 구하라.
Solution
즉
풀이 끝.
3.7 The Hypergeometric Probability Distribution
초기하분포
(표본공간에는 2가지의 표본만 존재한다)
전체 표본 개수가
3.8 The Poisson Probability Distribution
포아송 분포(푸아송 분포)
일주일 동안 자동차 사고의 횟수의 확률분포를 알아보자. 먼저 구간(일주일)을 작은 구간(subinterval)으로 쪼개서 해당 구간에는 사고가 딱 한번(혹은 0번) 발생할 수 있다고 하자. subinterval에서 2번 이상 사고가 날 확률은

Example 3.22
한달에 3번 발생하고 포아송 과정을 따르는 산업재해가 있다. 지난 2달 동안 재해는 10번 발생했다.
만약 한달 평균 사고 발생 횟수가 3(
Solution
2달동안 사고가 발생했으므로
(표, 프로그램을 이용하면)
3.9 The Moments and Moment-Generating Functions
적률, 적률생성함수
모수
'스터디 > 확률과 통계' 카테고리의 다른 글
| [확률] 베이즈 정리 (Bayes' theorem) (0) | 2023.02.18 |
|---|---|
| Chapter 10. Hypothesis Testing (0) | 2022.08.24 |
| Chapter 9. Properties of Point Estimators and Methods of Estimation (0) | 2022.08.13 |
| Chapter 8. Estimation (0) | 2022.08.05 |
| Chapter 4. Continuous Variables and Their Probability Distributions (0) | 2022.07.30 |



