
Decision Tree in Scikit learn
사이킷런 공식 문서에 따르면, 사이킷런의 Decision Tree는 CART 알고리즘을 바탕으로 최적화되어 구현되어있다.
그러나 categorical variable을 더이상 지원하지 않는다.
https://scikit-learn.org/stable/modules/tree.html#tree-algorithms-id3-c4-5-c5-0-and-cart
Decision Tree Tutorial with Iris dataset
사이킷런의 붓꽃 데이터셋을 이용하여 간단하게 decision tree를 학습해보자.
load dataset and fit the classifier
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
iris = load_iris()
X = iris.data[:, 2:] # petal length and width
y = iris.target
tree_clf = DecisionTreeClassifier(max_depth=2, random_state=42)
tree_clf.fit(X, y)사이킷런에서 가져온 데이터셋은 data로 X를, target으로 y에 접근할 수 있다.
Visualize the decision tree
decision tree가 어떻게 생겼는지(어떤 feature로 split되었는지) 시각화해보자.
sklearn.tree로도 plot할 수 있지만, graphviz를 이용할 것이다.
from graphviz import Source
from sklearn.tree import export_graphviz
export_graphviz(
tree_clf,
out_file="iris_tree.dot",
feature_names=iris.feature_names[2:],
class_names=iris.target_names,
rounded=True,
filled=True
)
Source.from_file("iris_tree.dot")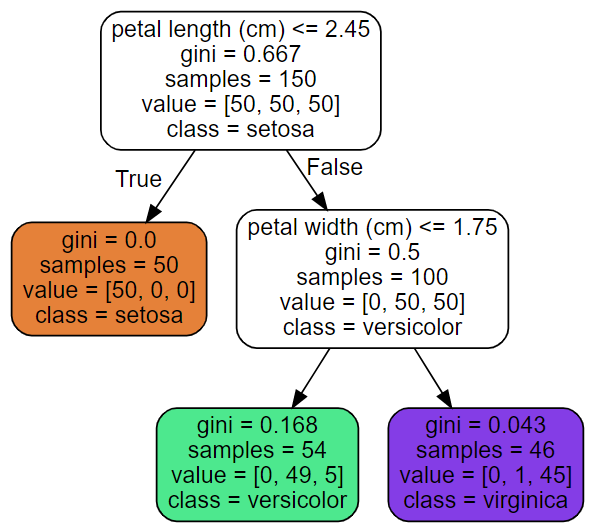
setosa class로 분류된 경우 gini=0으로 pure하다. (더이상 split하지 않는다)
versicolor와 virginica로 분류된 경우 완전히 pure하지 않지만 상당히 pure하다고 할 수 있다.
sample이 150밖에 되지 않기 때문에 tree의 크기가 그렇게 크지 않다.
Visualize the Decision Boundaries
변수 2개를 이용하여 학습했으므로 2차원 평면에 decision boundary를 그려보자.
from matplotlib.colors import ListedColormap
def plot_decision_boundary(clf, X, y, axes=[0, 7.5, 0, 3], iris=True, legend=False, plot_training=True):
x1s = np.linspace(axes[0], axes[1], 100)
x2s = np.linspace(axes[2], axes[3], 100)
x1, x2 = np.meshgrid(x1s, x2s)
X_new = np.c_[x1.ravel(), x2.ravel()]
y_pred = clf.predict(X_new).reshape(x1.shape)
custom_cmap = ListedColormap(['#fafab0','#9898ff','#a0faa0'])
plt.contourf(x1, x2, y_pred, alpha=0.3, cmap=custom_cmap)
if not iris:
custom_cmap2 = ListedColormap(['#7d7d58','#4c4c7f','#507d50'])
plt.contour(x1, x2, y_pred, cmap=custom_cmap2, alpha=0.8)
if plot_training:
plt.plot(X[:, 0][y==0], X[:, 1][y==0], "yo", label="Iris-Setosa")
plt.plot(X[:, 0][y==1], X[:, 1][y==1], "bs", label="Iris-Versicolor")
plt.plot(X[:, 0][y==2], X[:, 1][y==2], "g^", label="Iris-Virginica")
plt.axis(axes)
if iris:
plt.xlabel("Petal length", fontsize=14)
plt.ylabel("Petal width", fontsize=14)
else:
plt.xlabel(r"$x_1$", fontsize=18)
plt.ylabel(r"$x_2$", fontsize=18, rotation=0)
if legend:
plt.legend(loc="lower right", fontsize=14)함수 파라미터
- clf: DecisioinTreeClassifier
- X: 분류기 모델의 input이 되는 X
- y: 분류기 모델의 output과 대응되는 true y
- axes: x1축과 x2축의 min-max 범위를 지정. default로 x1축의 범위는 [0, 7.5], x2축의 범위는 [0, 3]으로 한다. (petal length와 petal width의 범위와 같다.)
- iris=True: iris dataset을 사용하는 것을 defalut로 한다.
- legend=False: 범례 표시를 하지 않는 것을 default로 한다.
- plot_training=True: (모델의 예측값이 아니라) training set(X, y)을 사용하는 것을 default로 한다.
공통 코드
- axes로 넘겨받은 배열을 이용하여 2개의 축의 범위를 100개로 나눈다. (np.linspace)
- x1, x2 2개의 축으로 grid space를 만든다. (np.meshgrid)
- 격자 공간에 있는 모든 점(100*100개)들을 미리 학습된 clf의 input으로 하여 클래스 y_pred를 얻는다.
- custom_map: 연노란색, 연보라색, 연녹색으로 미리 3가지 색을 지정한다.
- coutourf를 이용하여 등치선을 구성한다. (decision boundary가 단순하여 격자모양으로 나뉠 것이다) 위 decision tree의 결과를 보면 petal_length가 2.45, petal_width가 1.75가 경계가 됨을 알 수 있다.

plot_training) class가 [0, 1, 2]인 경우 각각 [yo(노란색+동그라미), bs(파란색+네모), g^(녹색+세모)]로 클래스를 나타낸다.
legend) 범례의 위치는 우하단(lower right)이고, 글자 크기는 14이다.

plt.figure(figsize=(8, 4))
plot_decision_boundary(tree_clf, X, y)
plt.plot([2.45, 2.45], [0, 3], "k-", linewidth=2)
plt.plot([2.45, 7.5], [1.75, 1.75], "k--", linewidth=2)
plt.plot([4.95, 4.95], [0, 1.75], "k:", linewidth=2)
plt.plot([4.85, 4.85], [1.75, 3], "k:", linewidth=2)
plt.text(1.40, 1.0, "Depth=0", fontsize=15)
plt.text(3.2, 1.80, "Depth=1", fontsize=13)
plt.text(4.05, 0.5, "(Depth=2)", fontsize=11)
plt.show()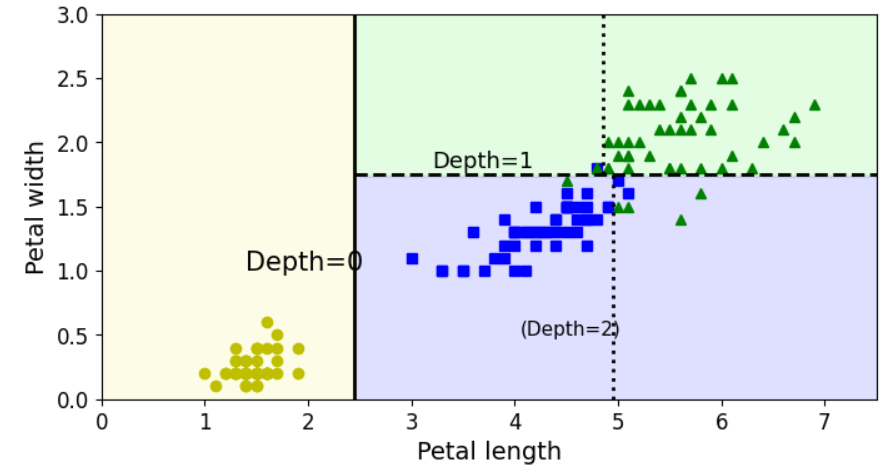
Predicting classes and class probabilities
tree_clf의 input이 2변수이므로 2개의 숫자를 입력으로 하면 분류기가 클래스를 뱉어줄 것이다.
[5, 1.5]를 입력으로 하면 (위 decision boundary를 보면) 1번 클래스 (2번째 클래스)를 예측할 것이다.
tree_clf.predict_proba([[5, 1.5]])
# array([[0. , 0.90740741, 0.09259259]])
tree_clf.predict([[5, 1.5]]) # return array index that has highest probability
# array([1])Note: 사이킷런의 대부분의 모델은 fit으로 학습하고, predict와 predict_proba로 예측하는 동일한 인터페이스를 갖는다.
Sensitivity to training set details
학습한 데이터 중에서 가장 길이가 긴 데이터만 제외한 149개 데이터를 이용하여 학습한 tree_clf_tweaked의 decision boundary를 살펴보자.
# widest Iris versicolor flower
X[(X[:, 1]==X[:, 1][y==1].max()) & (y==1)] # array([[4.8, 1.8]])
not_widest_versicolor = (X[:, 1]!=1.8) | (y==2)
X_tweaked = X[not_widest_versicolor]
y_tweaked = y[not_widest_versicolor]
tree_clf_tweaked = DecisionTreeClassifier(max_depth=2, random_state=40)
tree_clf_tweaked.fit(X_tweaked, y_tweaked)plt.figure(figsize=(8, 4))
plot_decision_boundary(tree_clf_tweaked, X_tweaked, y_tweaked, legend=False)
plt.plot([0, 7.5], [0.8, 0.8], "k-", linewidth=2)
plt.plot([0, 7.5], [1.75, 1.75], "k--", linewidth=2)
plt.text(1.0, 0.9, "Depth=0", fontsize=15)
plt.text(1.0, 1.80, "Depth=1", fontsize=13)
plt.show()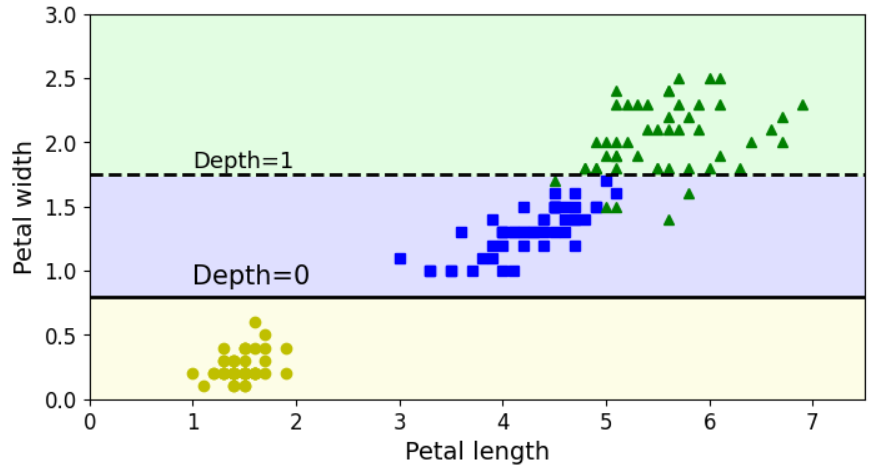
보도시피, DecisionTree는 training data의 작은 변화(심지어 데이터 1개만 제거)에도 매우 민감하다.
게다가 random_state로 고정하지 않으면 학습할 때마다 다른 결과를 얻는다.
Note: RandomForest와 같은 앙상블모델은 많은 tree를 averaging하기 때문에 이러한 instability를 어느정도 제한한다.
Decision Tree's Parameters
자주 사용되는 decision tree의 parameter는 아래와 같다.
참고: https://scikit-learn.org/stable/modules/generated/sklearn.tree.DecisionTreeClassifier.html
- max_depth: 트리의 최대 깊이
- min_samples_split: 노드가 split하기 위한 최소 sample 개수
- min_samples_leaf: leaf node가 가져야 하는 최소 sample 개수
- min_weight_fraction_leaf: min_samples_leaf와 동일하지만 정수가 아니라 비율(fraction)으로 지정
- max_leaf_nodes: leaf node의 최대 개수
- max_features: 각 노드마다 평가되어야 하는 최대 feature 개수
Decision tree on Moon-shape data
달 모양 데이터셋에 대하여 파라미터에 따른 DecisionTreeClassifier 2개를 비교해보자.
from sklearn.datasets import make_moons
Xm, ym = make_moons(n_samples=100, noise=0.25, random_state=53)
deep_tree_clf1 = DecisionTreeClassifier(random_state=42)
deep_tree_clf2 = DecisionTreeClassifier(min_samples_leaf=4, random_state=42)
deep_tree_clf1.fit(Xm, ym)
deep_tree_clf2.fit(Xm, ym)
plt.figure(figsize=(11, 4))
plt.subplot(121)
plot_decision_boundary(deep_tree_clf1, Xm, ym, axes=[-1.5, 2.5, -1, 1.5], iris=False)
plt.title("No restrictions", fontsize=16)
plt.subplot(122)
plot_decision_boundary(deep_tree_clf2, Xm, ym, axes=[-1.5, 2.5, -1, 1.5], iris=False)
plt.title("min_samples_leaf = {}".format(deep_tree_clf2.min_samples_leaf), fontsize=14)
plt.show()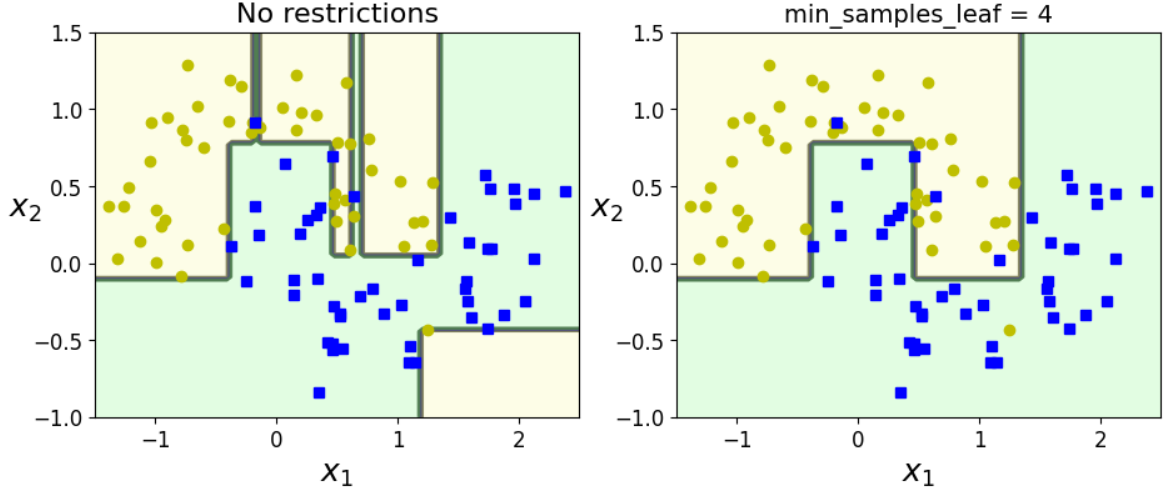
좌측은 기본 DecisionTreeClassifier의 decision boundary이다. trainset에 대하여 overfitting이 된 것을 알 수 있다.
우측은 DecisionTreeClassifier의 min_samples_leaf 4로 한정한 결과이다. 기본 모델에 비해 generalization이 잘 된 것을 알 수 있다.
Examples
(a) Generate a moons dataset
using makes_moons(n_samples=10000, noise=0.4). and add random_state=42 to make output constant
from sklearn.datasets import make_moons
X, y = make_moons(n_samples=10000, noise=0.4, random_state=42)(b) Split it into a training set and a test set
using train_test_split()
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
(c) Use grid search with cross-validation (GridSearchCV) to find good hyperparameter values
Hint: try various values for max_leaf_nodes
from sklearn.model_selection import GridSearchCV
params = {'max_leaf_nodes': list(range(2, 100)), 'min_samples_split': [2, 3, 4]}
grid_search_cv = GridSearchCV(DecisionTreeClassifier(random_state=42), params, n_jobs=-1, verbose=1, cv=3)
grid_search_cv.fit(X_train, y_train)
grid_search_cv.best_estimator_
(d) Train it on the full training set using these hyperparameters, and measure the model's performance on the test set.
Default로, GridSearchCV는 best model로 전체 training set으로 학습할 것이다. (refit=False 로 바꿀 수 있다)
best_estimator를 사용할 거라면 굳이 재학습하지 않아도 된다.
from sklearn.metrics import accuracy_score
# It use the best model by default
y_pred = grid_search_cv.predict(X_test)
accuracy_score(y_test, y_pred) # 0.8695
'스터디 > 데이터사이언스' 카테고리의 다른 글
| [Data Science] Linear Regression (0) | 2023.05.12 |
|---|---|
| [Data Science] Bayesian Classifier (0) | 2023.05.03 |
| [Data Science] Decision Tree - Model Evaluation (Confusion Matrix, Metric, ROC Curve, AUC Score) (0) | 2023.04.30 |
| [Data Science] Decision Tree - Overfitting (0) | 2023.04.29 |
| [Data Science] Decision Tree - Information Gain, Gain Ratio (0) | 2023.04.29 |



