\[ f(\mathbf{x}) = w_0 + w_1 x_1 + w_2 x_2 + \dots \]
위의 형태로 선형 데이터를 fitting하는 모델을 선형회귀(linear regression)이라 한다.
또는 아래와 같이 표현하기도 한다.
\[ y = \beta_0 + \beta_1 x_1 + \cdots + \epsilon \]
objective function
minimize the squared error
squared error는 large error에 대하여 더 penalize한다.
그러나 data sensitive하다는 단점이 있다. (erroneous data, outliers, etc.)
Least Squares Method (최소제곱법, 최소자승법)
least square criterion을 이용하여 선형회귀식의 계수를 구할 수 있다.
간단히 변수가 하나인 선형회귀를 생각해보자. ($y = \beta_0 + \beta_1 x_1$)
$n$개의 데이터 $x_1, \dots, x_n$을 이 모델에 피팅해보자.
먼저 slope $\hat{\beta_1}$를 구해보자.
$S_{xy} = \sum_{i=1}^{n}(x_i - \overline{x}) (y_i - \overline{y})$ 라 하면
\[ \hat{\beta_1} = \cfrac{S_{xy}}{S_{xx}} \]
그리고 intercept (절편)를 구하면 다음과 같다.
\[ \hat{\beta_0} = \overline{y} - \hat{\beta_1}\overline{x} \]
TSS, ESS, RSS
TSS: Total Sum of Squares. (총 제곱합)
ESS: Explained Sum of Squares (SS due to Regression). $\hat{y}$과 $\overline{y}$의 SS의 합. 모델이 설명하는 오차.
RSS: Residual Sum of Squares (SS due to Residual): $\hat{y}$와 $y$(true value)와의 SS의 합. 모델이 설명하지 못하는 잔차.
\begin{align*} ESS &= \sum_{i=1}^{n} (\hat{y}_i - \overline{y})^2 \\ RSS &= \sum_{i=1}^{n}(\hat{y}_i - y_i)^2 \\ TSS &= \sum_{i=1}^{n}(y_i - \overline{y})^2 \\ &= ESS + RSS \end{align*}

Model Selection
RMSE (Root Mean Squared Error)
\[ RMSE = \sqrt{\cfrac{1}{n}\sum_{i=1}^{n}(y_i - \hat{y}_i)^2 } \]
R-squared: Ratio of Explained Error
\[ R^2 = \cfrac{ESS}{TSS} = \cfrac{TSS - RSS}{TSS} = 1 - \cfrac{RSS}{TSS} \in [0, 1] \]
모델의 설명력을 의미한다. (설명력) = (설명 가능) / (전체)
F-test
F-test는 데이터가 같은 분포에 있는지 확인하는 검정이다.
$p$는 독립변수의 개수($x_1, x_2, \dots, x_p$가 존재)이고 $n$은 표본의 개수일 때
\[ F = \cfrac{\text{Explained Variance}}{\text{Unexplained Variance}} = \cfrac{\text{Mean of ESS}}{\text{Mean of RSS}} = \cfrac{ESS/p}{RSS/(n-p-1)} \]
Key Assumptions
선형회귀에서 독립변수는 $x_1, x_2, \dots$이고 종속변수는 예측하고자 하는 변수 $y$이다.
- Independence (독립성): 독립변수들 간의 (상관관계가 없이) 독립이어야 한다.
- Normality (정규성): 종속변수는 정규분포를 이룬다.
- Homoscedasticity (동분산성, 등분산성): 종속변수의 분산은 동일해야 한다. Residual이 특정 패턴을 보이지 않아야 한다.
- Linearity (선형성): 독립변수와 종속변수와의 관계는 선형적이어야 한다.
Checking the assumptions and violations
Independence (독립성)
데이터를 수집(생성)할 때 독립성이 보장되는지 확인
Normality (정규성)
$y$의 히스토그램을 통해 정규분포인지 눈으로 확인한다.
Normal Q-Q plot을 통해 정규성을 확인한다. (normal이라면 $y=x$와 유사한 직선으로 분포한다.

Homoscedasticity (등분산성)
Residual과 Fitted (predicted)를 확인한다.

Linearity (선형성)
scatter plot을 통해 선형관계를 눈으로 확인한다.
또는 residual 과 fitted를 확인한다.
Sample size (표본의 크기)
일반적으로 $n>30$을 만족해야 정규성을 만족하는 것으로 한다.
Multi-collinearity (다중 공선성)
VIF (Variance Influence Factor, 분산 팽창 요인)를 이용한다.
보통 VIF > 10이면 다중공선성으로 판단한다. (해당 변수는 제거하는 것이 좋다)
Auto-correlation (자기상관성)
Durbin-Watson test를 이용할 수 있다.
통계량은 $DW$로 표기하며 범위는 $DW \in [0, 4]$이다.
$DW$가 $2$에 가까우면 neutral하여 자기상관성이 없다고 판단한다.
($0$에 가까울 수록 양의 자기상관성, $4$에 가까울수록 음의 자기상관성을 갖는다고 판단)
귀무가설 $H_0$은 "자기상관관계가 없다" 이고, 대립가설 $H_a$는 "자기상관관계가 있다" 이다.

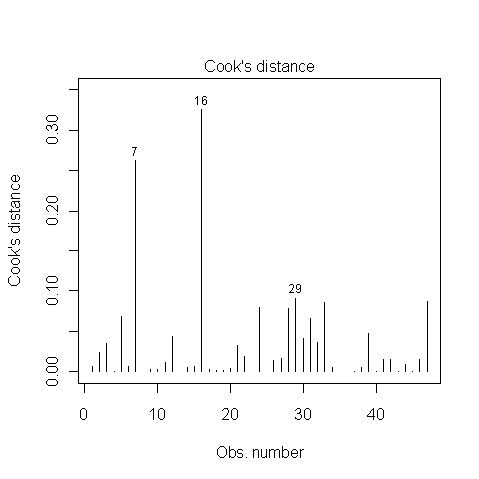
Outliers (이상치)
Cook's distance를 이용할 수 있다. 쿡거리가 특정 기준을 넘으면 이상치로 판정한다.
'스터디 > 데이터사이언스' 카테고리의 다른 글
| Dummy coding, Effect Coding (0) | 2023.05.15 |
|---|---|
| [Data Science] Logistic Regression (0) | 2023.05.14 |
| [Data Science] Bayesian Classifier (0) | 2023.05.03 |
| [Data Science] Decision Tree in Python (with Scikit-learn) (0) | 2023.05.01 |
| [Data Science] Decision Tree - Model Evaluation (Confusion Matrix, Metric, ROC Curve, AUC Score) (0) | 2023.04.30 |



