Basic Concepts of BIRCH
BIRCH (Balanced Iterative Reducing and Clustering Using Hierarchies)
Clustering Feature Tree(CF-Tree)를 점진적으로 증가시켜 데이터의 계층을 구성한다.
(1) 데이터를 scan하여 CF tree를 구성한다.
(2) arbitrary clustering 알고리즘을 이용하여 CF-tree의 leaf node를 cluster로 한다.
Scales Linearly
single scan만으로도 좋은 클러스터링이 가능하다.
약간의 추가적인 scan으로 더 좋은 퀄리티 향상이 가능하다.
전체적인 시간복잡도는
Weakness
numeric data만 적용할 수 있다.
데이터 순서에 민감하다. (sensitive to the order of the data record)
Similarity Metric
Centroid
Note: 논문에서는 centroid를라 하지 않고 로 표기하였다.
Radius: centroid로부터의 평균거리
Diameter: pair-wise의 평균거리
이를 바탕으로
Centroid Euclidean Distance
Centroid Manhattan Distance
Average inter-cluster
Average intra-cluster
Variance increases
Clustering Feature
BIRCH 알고리즘은 data set을 scan할 때 CF tree (Clustering Feature tree)를 만든다.
각 CF tree의 entry는 3-tuple로 이루어져있다.
이때
Note:는 벡터고, 는 스칼라가 된다.

Properties of Clustering Feature
CF는 몇가지 성질이 있는데 이는 이후 CF-tree를 만들 때 계산이 용이하다.
(1) CF entry는 compact하다. (storage 측면에서 매우 효율적이다)
(2) CF entry는
(3) CF Additivity Theorem:
CF-Tree
- CF-tree는 height-balanced tree이다. (height-balanced tree in which each leaf node contains a sub-cluster)
- non-leaf node는 children을 갖는다.
- non-leaf node는 children의 모든 CF의 합이다.
- CF-tree는 2개의 parameter를 갖는다.
- Branching factor (
- Threshold (
- Branching factor (
BIRCH Algorithm
BIRCH clustering algorithm은 4개의 phase로 구성된다.
Phase 1: Building a CF-Tree
main task는 scan all data, build an initial in-memory CF tree, recycling space on disk. 이다.
초기 threshold
Note: B+-tree를 구성하는 방법과 유사하다.
- 각 data point에 대하여, CF root node와 비교하여 가장 유사한(distance가 작은) root node를 찾는다.
- 해당 root node에서 descend down하여 non-leaf node와도 똑같이 비교한다.
- 해당 non-leaf node에서 descend down하여 leaf node에서도 똑같이 비교한다.
- new data point를 포함한 leaf node의
- 4-2를 했다면,
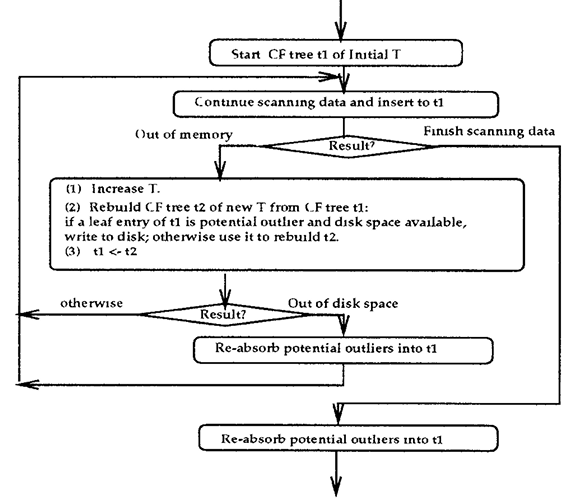
Phase 3: Global Clustering
CF tree의 leaf node가 cluster가 된다.
Summary of BIRCH
Concerns
- sensitive to insertion order
- leaf node의 size가 고정되어있기 때문에, cluster는 natural하지 않을 수 있다.
- radius, diameter 때문에 cluster는 spherical할 경향이 있다. (spherical shape가 아니라면 BIRCH가 잘 동작하지 않을 수 있다.)
Summary
- data space is usually not uniformly occupied. (not every data is equally importance for clustering)
- I/O cost를 최소화(efficiency 향상)하는 대신에 memory usage는 최대화(accuracy 향상)한다.
참고
BIRCH: An Efficient Data Clustering Method for Very Large Databases. Tian Zhang, Raghu Ramakrichnam, Miron Livny.
'스터디 > 인공지능, 딥러닝, 머신러닝' 카테고리의 다른 글
| [Clustering] Density-Based Methods, DBSCAN (0) | 2023.05.25 |
|---|---|
| [CS224w] Training Graph Neural Networks (0) | 2023.05.24 |
| [Clustering] Hierarchical Clustering (계층적 군집화) (0) | 2023.05.22 |
| [Clustering] Drawbacks of K-means and Solutions with Python (K-means 단점과 해결방법) (0) | 2023.05.21 |
| [Clustering] K-means Clustering in Python (K-means 알고리즘) (0) | 2023.05.20 |



