Idea
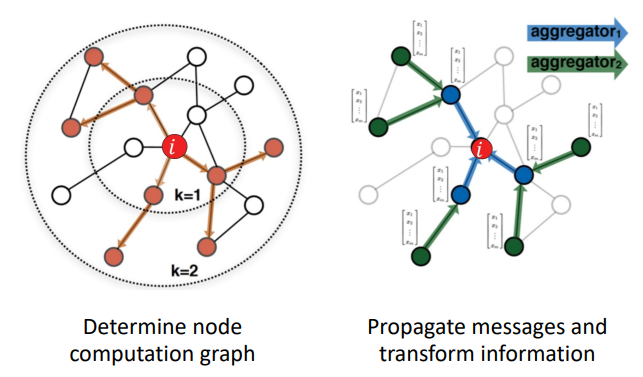
node의 neighborhood는 computation graph를 정의한다.
message는 relational information과 attribute information 모두 포함할 수 있다.
Neighborhood Aggregation
node는 이웃 노드의 정보를 neural network를 통해 정보를 집계한다.
모든 노드는 이웃 노드로부터 정의된다.
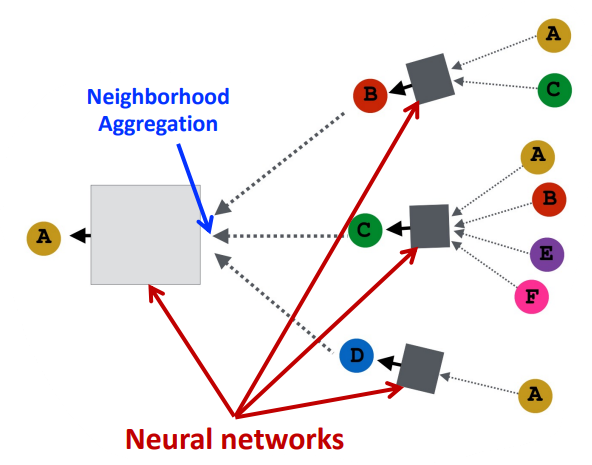
그렇다면 어떤 Neural Network를 사용할 것인가? 어떻게 집계할 것인가?
GCN, Graph Convolutional Network
Basic Approach
어떤 neural network를 사용할 것인가? → weight matrix를 사용하는 기본형태. $\mathbf{B}$와 $\mathbf{W}$를 사용할 것이다.
어떤 종류의 집계함수를 사용할 것인가? → Average
시작레이어인 $\mathbf{h}_v^0$은 노드 $v$의 feature node인 $x_v$를 사용한다.
최종적으로 $L$번째 레이어를 통과한 것은 $\mathbf{z}_v = \mathbf{h}_v^{(L)}$이다.

Matrix Formulation
기본 구조를 갖는 GCN의 경우, 행렬 연산으로만으로 표현할 수 있다.

$\tilde{\mathbf{A}}$가 희소행렬이기 때문에, 행렬 곱셈이 효과적으로 동작한다.

Training
최종적으로 얻은 임베딩 $\mathbf{z}_v$를 loss function의 입력으로 넘기고, SGD를 이용하여 weight parameter를 최적화한다.
(1) Supervised Loss
지도학습의 경우, 일반적으로 우리가 아는 Machine Learning처럼 정의하면 된다.

regression:
$\mathcal{L}$: squared error
$y$: real number
$f_{\theta}$: regressor
classification
$\mathcal{L}$: cross entropy
$y$: categorical
$f_{\theta}$: classifier

Ground truth label인 $y_v$와 model prediction 결과인 $f_{\theta}(\mathbf{z}_v)$를 이용하여 지도학습을 진행한다.

(2) Unsupervised Loss
비지도학습의 경우, node label이 없기 때문에, 그래프 구조 자체를 supervision으로 한다.
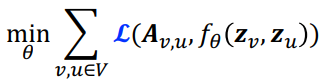
$\mathcal{L}$: cross entropy
$\mathbf{A}$: 인접행렬(adjacency matrix). 노드 $u$와 $v$ 사이에 edge가 있다면 $\mathbf{A}_{v, u}=1$이다.
$\f_{\theta}$: Encoder

auto-encoder와 유사하게, 비지도학습에서는 그래프를 재구성하는 것으로 학습한다. (reconstruct the graph)
따라서 Ground truth label은 그래프 구조를 나타내는 인접행렬 $\mathbf{A}_{v, u}$, Model prediction 결과로는 인코더의 결과인 $f_{\theta}(\mathbf{z}_v, \mathbf{z}_u)$이다.

PyTorch Code
아래 포스팅 참고
https://trivia-starage.tistory.com/70
[CS224w] Colab 2 - PyG, OGB, GNN
Device 런타임 > 런타임 유형 변경 > 하드웨어 가속기 > GPU로 설정하고 저장 Setup import torch import os print("PyTorch has version {}".format(torch.__version__)) PyTorch has version 1.13.1+cu116 # Install torch geometric if 'IS_GRADES
trivia-starage.tistory.com
'스터디 > 인공지능, 딥러닝, 머신러닝' 카테고리의 다른 글
| [CS224w] Graph Augmentation (0) | 2023.04.24 |
|---|---|
| GAT, GraphSAGE (0) | 2023.04.19 |
| [논문리뷰] TimesNet, Temporal 2D-Variation Modeling for General Time Series Analysis (0) | 2023.04.08 |
| [CS224w] Colab 2 - PyG, OGB, GNN (0) | 2023.03.21 |
| [CS224w] 5. A General Perspective on GNNs (1), 이론편 (0) | 2023.03.11 |



