
Decision Tree
어떤 사람이 컴퓨터를 살지 (혹은 사지 않을지) 분류하는 모델의 개념도이다.
각 leaf 혹은 node는 속성(attribute)를 나타낸다. 만일 age=senior이고 credit_rating=yes 라면 이 사람은 컴퓨터를 산다는 예측을 할 것이다.
Tree Induction
Greedy Stragegy
어떤 기준으로 attribute test를 할 것인지 greedy한 방법으로 attribute 기준으로 데이터를 나눌 것이다.
Issues
어떻게 데이터를 나눌 것인가? (How to split?) - how to specify the attribute test condition?, how to determine the best split?
언제까지 데이터를 나눌 것인가? (When to stop?)
How to specify Test Condition?
Attribute Type에 따라 나눌 수 있다. 크게 3가지로, Nominal, Ordinal, Condituous에 따라 다르다.
또한 split 방법도 2개 혹은 여러개로 나눌 수 있다.
Splitting Based on Nominal Attributes
Multi-way split은 구별되는 값으로 많은 partition을 만드는 것이다. 아래 그림을 보면, CarType이라는 nominal attribute를 3개의 brach로 나눈 것이다.
Binary split은 branching을 할 때 2개의 집합으로 파티션을 나누는 것이다. 이 경우, 최적의 partitioning을 찾아야 성능이 좋다 아래 그림은 CarType을 {Family, Luxury}와 {Sports} 2개로 분기한 것이다.
Splitting Based on Ordinal Attributes
Ordinal attribute 역시 Multi-way split이 가능하다.
그러나 Binary split의 경우, 주의할 것이 있다. 같은 subset끼리 적절한 range를 가져야 한다. ordinal value는 순서가 있기 때문에, 같은 partition은 연속된 순서를 가져야 의미를 갖는다.
Splitting Based on Continuous Attributes
Multi-way split의 경우, discritization을 이용하여 여러 구간에 대한 partition을 만들 수 있다.
Binary-way split의 경우, 가능한 모든 값에서 split이 가능하다. 따라서 최적의 split 지점을 찾는 것이 중요하다.
그렇다면, 어떻게 split하는 것이 좋은 것일까?
{C0, C1} 이렇게 두 가지 분류해야할 클래스가 있다고 하자.
그리고 3가지 attribute에 따라 다음과 같이 클래스가 분류된다고 하자.
어떤 attribute가 좋게 split되었다고 할 수 있을까?
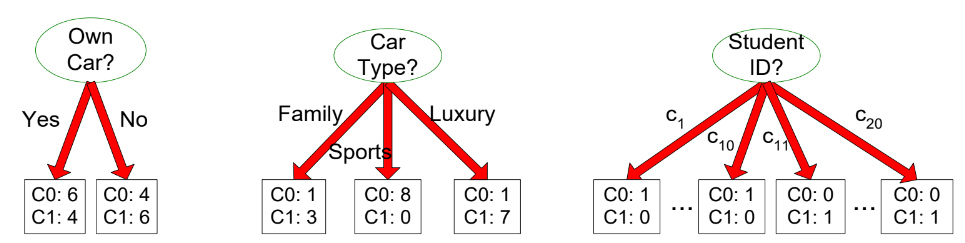
Node Impurity, 노드 불순도
Greedy approach: 각 노드는 (가급적) 같은 클래스끼리 분류되어야 한다. (homogeneous clss distribution)
만일
Node impurity를 이용하여 best split을 구하면 된다.
데이터 유사도와 같이, node impurity를 계산하는 방법도 여러가지 존재한다.
이에 대한 내용은 다음 포스팅에서 이어진다.
'스터디 > 데이터사이언스' 카테고리의 다른 글
| [Data Science] Association Rule Mining - Excercises (1) | 2023.04.17 |
|---|---|
| [Data Science] Decision Tree - GINI index와 CART 알고리즘 (0) | 2023.04.16 |
| Entropy의 의미 (정보이론) (0) | 2023.04.14 |
| [Pandas] iloc와 loc 차이점 (0) | 2023.04.12 |
| [Python] 선형회귀 모델링 (0) | 2023.04.12 |


