
Ready
다이아몬드 데이터셋을 이용할 것이다.
df = sns.load_dataset('diamonds')
df.head()Histogram
x: array of sequence
bins: (default=10) 히스토그램의 binning 개수
plt.hist(df['price'], bins=8)
# plot as a probability density
plt.hist(df['price'], bins=8, density=True)seaborn에도 히스토그램을 지원한다.
distplot - 히스토그램+density. 그러나 deprecated. seaborn의 이후 추가된 함수들과 distplot의 API가 너무 달라서 그렇다고 한다.
displot과 histplot을 이용하도록 하자. (kde=True)를 인자로 넘겨주면 density를 그릴 수 있다.
histplot의 경우, bins는 자동으로 계산되지만, 임의로 설정할 수 있다.
sns.distplot(df['price'])
sns.histplot(df['price'])
sns.histplot(df['price'], bins=20, kde=True)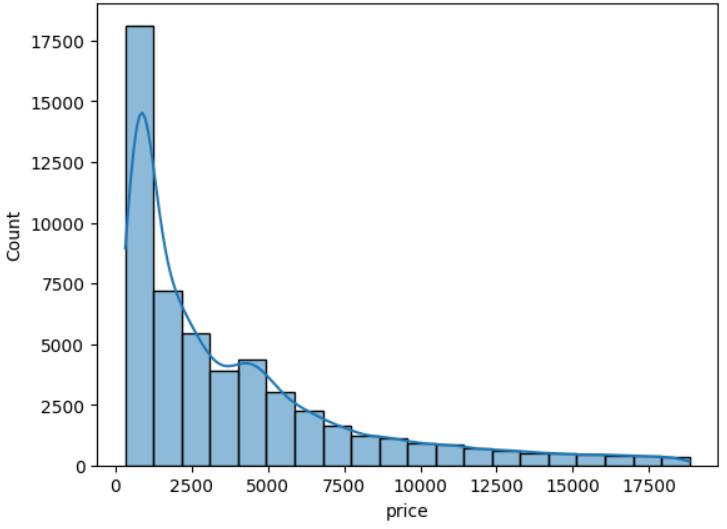
barplot
barplot은 categorical attribute에 적합한 그래프이다. 각 class 별로 얼마나 많이 있는지 개수를 시각화한다.
기본적으로 pandas의 dataframe의 plot(kind='bar')를 이용하여 막대그래프를 그릴 수 있다. 이때 직접 groupby로 카테고리 데이터의 개수(count)로 값을 구한 후에 적용해야 한다.
두번째 방법은 seaborn의 estimator를 이용하는 것이다. data, x축, y축은 동일하게 지정하되, estimator=len을 인자로 넘겨주면 categorical data의 개수를 계산해준다.
estimator=np.mean, estimator=np.median 등 estimator에는 함수를 넘겨주면 된다.
# method 1. use pandas dataframe plot()
df.groupby('cut')['price'].count().plot(kind='bar')
# method 2. use seaborn barplot with estimator=len
ax = sns.barplot(data=df, x='cut', y='price', estimator=len)
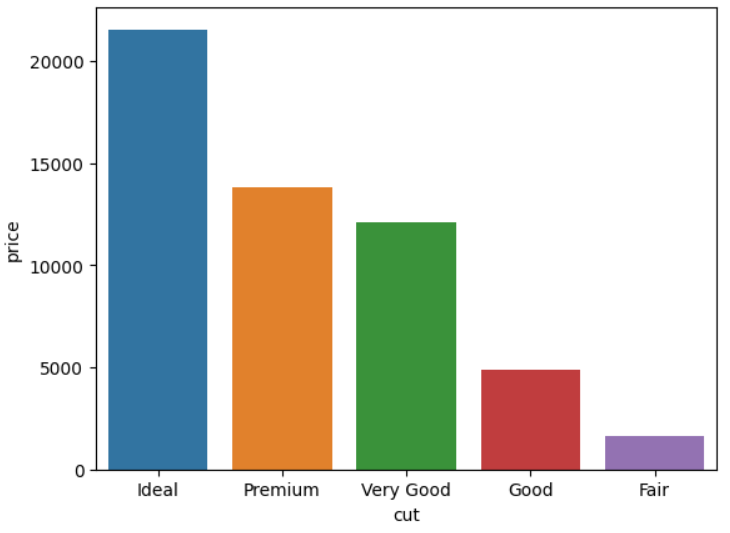
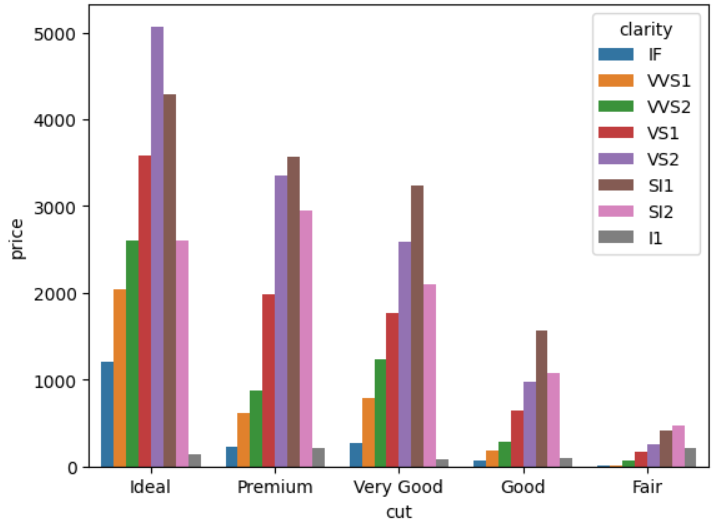
# method 3. use seaborn barplot with estimator=len and hue
ax = sns.barplot(data=df, x='cut', y='price', hue='clarity', estimator=len)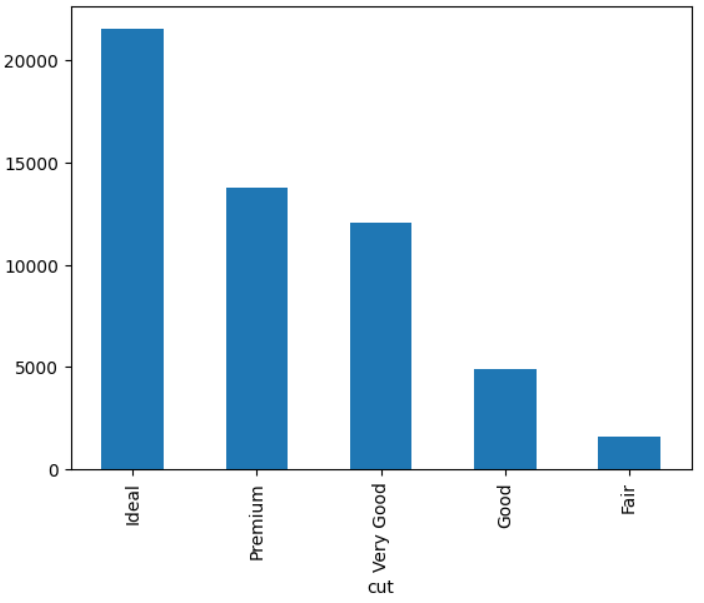
Violinplot
주로 numeric attribute에 사용하는 그래프이다. seaborn 도큐먼트에 따르면, boxplot과 whisker plot과 비슷한 역할을 한다고 한다. violin plot은 categorical 별 quantitative 데이터의 분포를 보여주는데 목적이 있다.
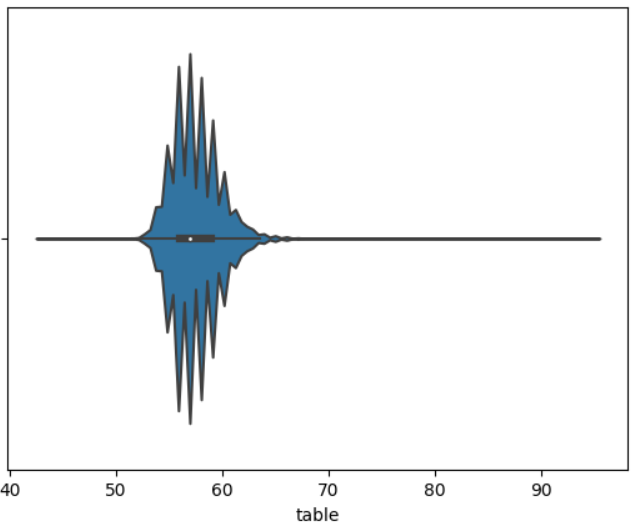
물론, 하나의 attribute에 대하여 대칭적인 분포를 그리는 violin plot을 보여줄 수도 있다.
sns.violinplot(data=df, x='cut', y='table', hue='clarity')
sns.violinplot(data=df, x='table')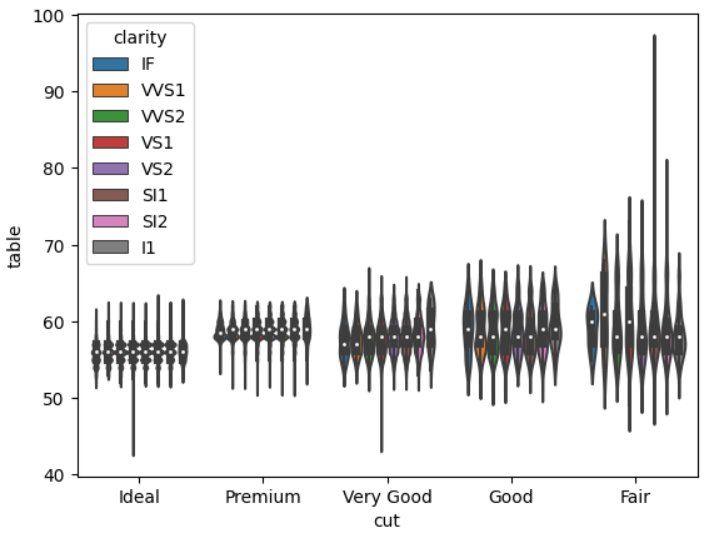
Scatterplot, Jointplot
scatterplot은 두 numeric 변수의 상관관계를 볼 때 적절한 그래프이다.
seaborn에는 jointplot으로 각 scatter로 상관관계 뿐만 아니라 각 데이터의 분포도 상단과 우측에 시각화한다.
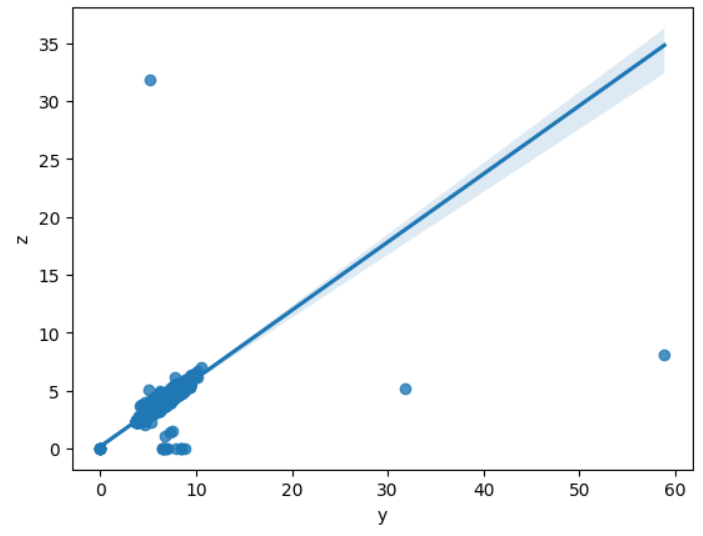
regplot은 두 변수의 선형회귀식을 구하여 선형그래프와 오차까지 시각화하는 함수이다.
# joint plot
sns.jointplot(data=df, x='table', y='depth')
# regression plot
sns.regplot(data=df, x='y', y='z')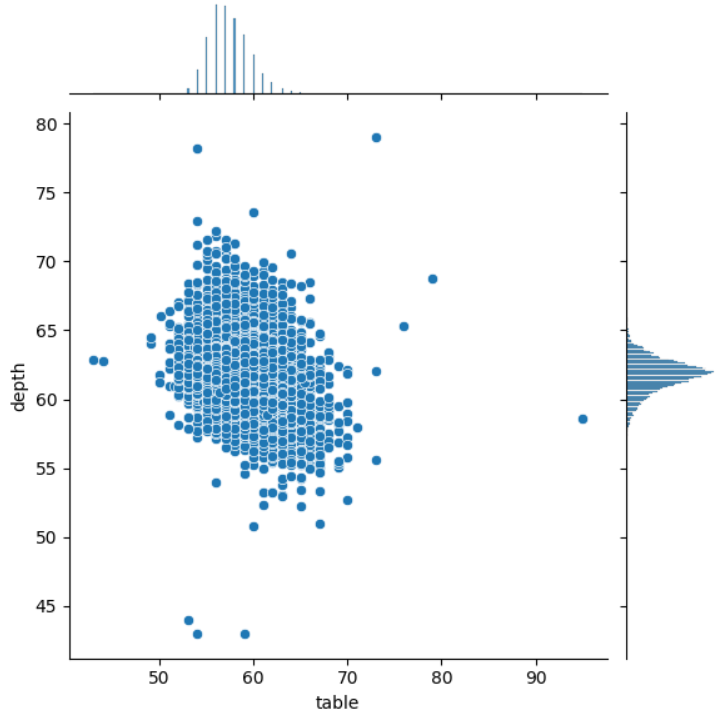
boxplot
boxplot은 5개의 수, 즉 min, Q1, Q2(=median), Q3, max와 IQR(Q3-Q1)을 시각화한 그래프이다.
min=Q1 - 1.5 * IQR, max=Q3 + 1.5 * IQR로 정의하고, [min, max]를 벗어나는 data point들을 outlier로 간주한다.
중앙값을 계산해야 하므로 당연히 numeric attribute에 적합하다.
sns.boxplot(data=df, x='cut', y='table')
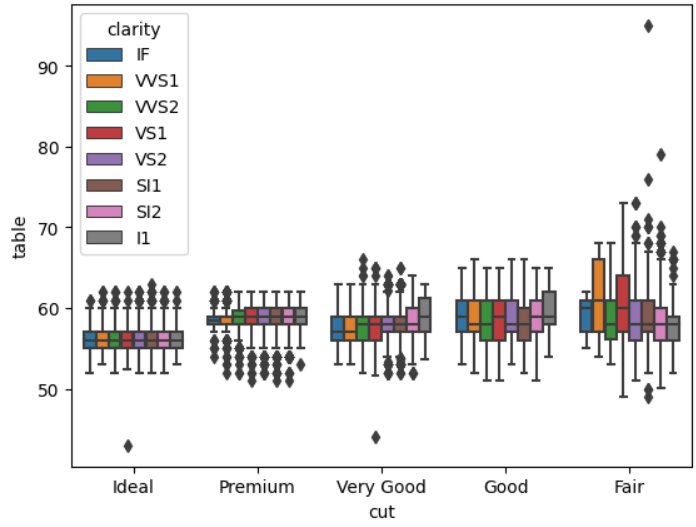
sns.boxplot(data=df, x='cut', y='table', hue='clarity')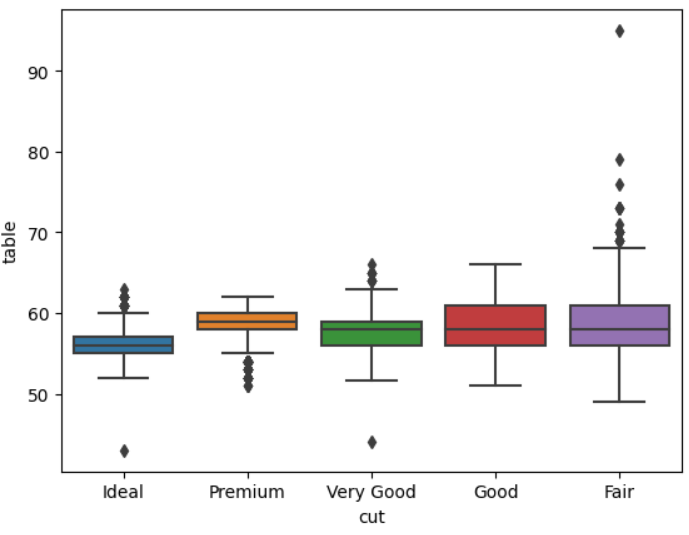
pairplot
모든 변수들의 scattor plot을 보여준다.
sns.pairplot(data=df)
'스터디 > 데이터사이언스' 카테고리의 다른 글
| [Pandas] iloc와 loc 차이점 (0) | 2023.04.12 |
|---|---|
| [Python] 선형회귀 모델링 (0) | 2023.04.12 |
| [Pandas] Basic Statistics 살펴보기 (0) | 2023.04.10 |
| [Data Science] Grubb's test를 이용한 Outlier detection (0) | 2023.04.08 |
| [Data Science] Association Rule Mining (7) mlxtend로 association rule을 만들어보자 (0) | 2023.04.04 |


