
Keywords
연속확률변수, 확률밀도함수, 균등분포, 지수분포, 감마함수, 감마분포, 베타함수, 베타분포, 표준정규분포, 정규분포, 카이제곱분포
Continuous Random Variable, probability density function, density, density function, uniform distribution, exponential distribution, gamma function, gamma distribution, beta function, beta distribution, standard normal distribution, normal distribution, chi-squared distribution
Continuous Random Variable
확률변수가 모든 실수 에 대하여 이면 연속확률변수하라고 한다.
Density function이고 이고 이면 함수 는 밀도함수(density function)라고 한다.
Note. 책이나 강의마다 density function을 probability density function(확률밀도함수, pdf, PDF)라고도 한다.
Absolutely Continuous
확률변수가 density function 에 대하여
이면 absolutely continuous라고 한다.
Note. density function의 height(함숫값)은 확률과 전혀 상관이 없다. 이 가능하다.
매우 작은 양수
따라서 다음이 성립한다.
확률변수가 absolutely continuous random variable일 때, 이 성립한다.
PROOF)
Uniform distribution, 균등분포,
Exponential distribution, 지수분포,
파라미터가
기계 등의 수명(life span)에 자주 사용되는 분포이다.
Memoryless Property, 무기억성(비기억성)
지수분포를 따르는 확률변수
PROOF)
Gamma distribution, 감마분포,
Gamma function, 감마함수
감마함수의 몇가지 성질
(1)
(1.1) 특히 자연수에 대하여 이다.
(1.2)
(2)
Note 1: 책에 따라 감마함수의 두 번째 파라미터를로 표기할 수 있다.
Note 2: 감마함수는 density function이 아니다.
Gamma function example
위의 (2.2)에 따라 감마함수의
Gamma density는 아래와 같이 정의된다. (이것이 감마분포의 pdf이다)
지수분포는 감마분포의
kernel of density
감마분포에 사용되는 PDF는 감마함수의 내부의 피적분함수의 적분 결과가
kernel of density로 이루어진 적분은 부분적분을 이용하지 않고도 간단하게(?) 계산할 수 있다.
감마분포의 확률밀도함수
(1)
(2)
(3)
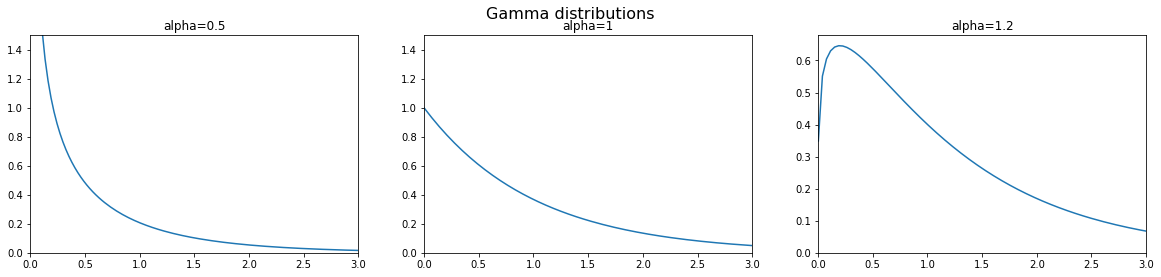
import numpy as np
from scipy.stats import beta
from scipy.stats import gamma
import matplotlib.pyplot as plt
params = [0.5, 1, 1.2]
x = [np.linspace(gamma.ppf(0.001, alpha), gamma.ppf(0.999, alpha), 200) for alpha in params]
fig, axes = plt.subplots(1, len(params), figsize=(20 ,4))
fig.suptitle('Gamma distributions', fontsize=16)
for i in range(len(params)):
axes[i].plot(x[i], gamma.pdf(x[i], params[i]))
axes[i].set_ylim(0, 1.5)
axes[i].set_xlim(0, 3)
if params[i] > 1:
axes[i].set_ylim(0, max(gamma.pdf(x[i], params[i]) * 1.05))
axes[i].set_title(f'alpha={params[i]}')
Beta distributin, 베타분포,
베타함수(
Bayesian statistics에서 자주 사용된다.
베타분포는 베타함수의 피적분함수의 적분결과가
kernel of density
베타분포에서도 베타함수 자체가 density하지 않기 때문에 적분의 결과가
(1)
베타분포의 확률밀도함수
(1)
(2)
(2.1)
(2.2)
(3)
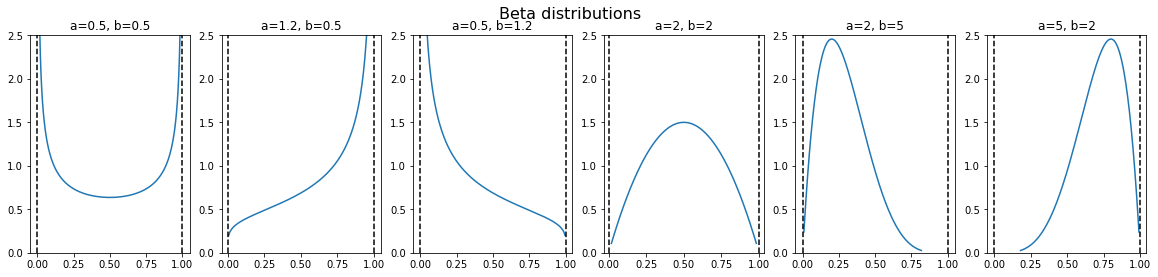
import numpy as np
from scipy.stats import beta
from scipy.stats import gamma
import matplotlib.pyplot as plt
params = [(0.5, 0.5), (1.2, 0.5), (0.5, 1.2), (2, 2), (2, 5), (5, 2)]
fig, axes = plt.subplots(1, len(params), figsize=(20 ,4))
fig.suptitle('Beta distributions', fontsize=16)
for ax, (a, b) in zip(axes, params):
x = np.linspace(beta.ppf(0.001, a, b), beta.ppf(0.999, a, b), 200)
ax.plot(x, beta.pdf(x, a, b))
ax.set_ylim(0, 2.5)
ax.axvline(x=0, linestyle='--', color='black')
ax.axvline(x=1.0, linestyle='--', color='black')
ax.set_title(f'a={a}, b={b}')
참고로
Normal distribution, 정규분포,
표준정규확률밀도함수(standard normal density)는
정규분포함수는 아래와 같다.
※
(1)
(2) 대칭성을 이용하여
kernel of density
앞의 density function들과 마찬가지로
앞의 density function의 예시와 마찬가지로, kernel을 이용하여 몇가지 함수의 적분을 쉽게(?) 구할 수 있다.
(1)
(2)
Empirical Rule
68-95-99.7 규칙이라고도 한다. (그 쉽다는 GRE quantitative에서도 이 세 숫자는 외워야 풀 수 있다.)
Chi-squared distribution,
Recall that
카이제곱 분포는 자유도(degrees of freedom)이라는 파리미터만 있고, 감마함수의 특별한 형태로 정의한다.
따라서 density function은
'스터디 > 확률과 통계' 카테고리의 다른 글
| 확률변수의 변환, Change of Variable (0) | 2023.03.21 |
|---|---|
| 누적분포함수, Cumulative Distribution Function (CDF) (0) | 2023.03.21 |
| 이산확률분포 그려보기 (Python) (0) | 2023.03.10 |
| Discrete Random Variables and Distributions (확률변수, 이산확률분포) (0) | 2023.03.09 |
| 중앙값 추정하기. Median of Grouped Data using Median Class (0) | 2023.03.07 |



