Word2Vec: Embedding the word
2013년 발표된 논문 "Efficient Estimation of Word Representations in Vector Space"도 벌써 10년이 되어간다. 딥러닝 모델을 이용한 임베딩 중 가장 유명한 방법론이 아닐까 싶다.
word2vec를 구현하는 방법은 CBOW(Continuous Bag-of-Words)와 skip-gram(Continuous Skip-gram)이 있고, 여기서는 skip-gram만 설명한다.

Target and Context
Key idea는 "같은 context에서 같이 등장하는 단어끼리는 의미가 가깝다"이다. 여기서 의미는 단어 그대로의 사전적 의미는 아니고 문맥적 의미라고 생각하면 되겠다. (like와 hate는 사전적 의미는 달라도 context가 유사하다)
context는 window size의 크기로 정의한다.
문장(혹은 문서, document)이 "I read sci-fi books and drink orange juice" 이고 window size=2라고 하자. 첫번째 단어부터 차례로 target word가 된다. target word를 기준으로 앞뒤 window size만큼이 context word가 된다.
아래 예시에서, "drink"가 target word일 때, context word는 "books", "and", "orange", "juice" 4개가 된다.

Architecture
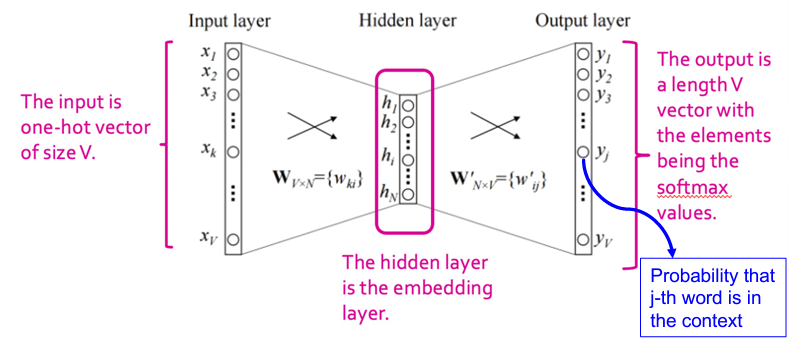
skip-gram을 사용하는 word2vec은 2-layer Neural Network이다. 이 NN의 input은 target word이고, output(predict)은 context words가 된다.
target word의 앞에 나온 context words는 history라 하고, target word의 뒤에 나온 context words는 future라고 한다.

단어집합(vocab)의 크기를 $V$라 하자. 그러면 input layer와 각 output layer의 크기는 $V$ 차원이다. 그리고 context word를 예측하도록 학습되므로 크기가 $V$인 softmax를 이용한다.
hidden layer의 차원은 $N$이라 하고 일반적으로 $N << V$이다. 그렇다면 2개의 weight matrix를 학습시키는 구조이다. (실제로는 window size만큼 학습해야할 weight matrix가 더 있지만, 설명을 위해 하나만 가져왔다.)
Notation
$V$: 단어의 개수. 단어 집합(vocabulary set)의 크기와 같다. engineering 관점에서 불용어 등을 제외한 것이다.
$N$: 임베딩 차원. 일반적으로 $N << V$이다. 논문에서 사용한 skip-gram의 경우 $N=300,\ 600, 1000$이고 $V=783M,\ 6B$이다.
$\mathbf{W}$: input-hidden의 가중치. shape은 $V \times N$ 이다.
$\mathbf{W}'$: hidden-output의 가중치. shape은 $N \times V$ 이다.
$\mathbf{x}$: 단어 벡터. 차원은 $V$이다.
$x^\top W$: word embedding vector.
Training the network
label이 없는 unsupervised learning이다. (실제 target에 대한 context word의 답이 정해진 것이 아님) 그래서 Fake task를 이용하여 학습한다. target word가 주어지면, context words를 예측하도록 한다.

Loss function
$x$와 $y$가 각각 input과 output일때, $y = \mathrm{softmax}(W'^\top W^\top x)$이다.
target word와 context word를 각각 $\mathbf{w}_t$, $\mathbf{w}_c$라 하자. ($\mathbf{W}가 아니다). 이들 벡터는 one-hot vector이므로 cross entropy로 loss를 정의할 수 있다.

Example
Word2Vec의 학습과정을 살펴보자. 간단히 하기 위해 toy dataset으로 문장 하나를 전체 document로 간주하자.
Document: "I read sci-fi books and drink orange juice"
vocab = {"I", "read", "sci-fi", "books", "and", "drink", "orange", "juice"}. 즉 $V=8$
embedding dimension: 3; $N=3$
초기화된 $\mathbf{W}$와 $\mathbf{W'}$가 다음과 같다고 하자.


target word="books"라 할 때 학습시켜보자. books의 벡터는 $\mathbf{x}_{\text{books}}=[0, 0, 0, 1, 0, 0, 0, 0]^\top$이므로
\[ \mathbf{x}^\top \mathbf{W} = [0.5, 2.3, 2.2] \]
\[ \mathbf{x}^\top \mathbf{W W'} = [1.0, 5.6, -2.4, 5.3, 6.1, 7.4, 3.0, 3.5] \]
이렇게 얻은 $\mathbf{x}^\top \mathbf{WW'}$로 softmax를 계산하면 predicted word는 drink이다.

만약에 해당 NN이 future-2를 예측하는 거라면 잘 예측한 것이 된다. back propagation 예시를 위해 지금 학습중인 NN이 past-2를 예측한다고 하자. 이 경우 true label은 "read"이므로 loss는 다음과 같다.

Summary and Results
- Skip-gram method는 비교적 적은 데이터로도 rare word의 represent(embedding)을 찾을 수 있다.
- CBOW method는 큰 데이터에 더 적합하고 자주 등장하는 단어의 representation을 잘 찾는다.
- embedding vector끼리의 연산은 의미적으로 유사한 연산의 결과를 갖는다.
- embedding을 구할 때 regression이나 classification에 구애받지 않는다.

'스터디 > 데이터사이언스' 카테고리의 다른 글
| [CS224w] Subgraphs and Motifs (0) | 2023.11.28 |
|---|---|
| [Community Detection] Girvan-Newman (GN) Algorithm (0) | 2023.11.14 |
| [CS246] TrustRank vs. LinkFarms (0) | 2023.11.06 |
| [CS246] Topic-Specific PageRank (0) | 2023.11.05 |
| [CS246] PageRank (0) | 2023.10.26 |



