
Large-scale Computing
supercomputer를 운용하는것은 너무 비용이 크고, 심지어 데이터 크기(scaling)를 크게 할 수 없다.
대신, 하드웨어를 연결하여 분산처리를 구현한다. (collection of commodity hardware)

Challenges
- distribute computation?
- distributed programs?
- machines fail
네트워크간 데이터 복사(copy)는 시간이 걸린다. local에 연산 결과를 저장하고, failure에 대비하여 여러번 저장한다.
Spark/Hadoop은 이런 문제를 해결할 수 있다.
- Storage Infrastructure: Google File System (GFS), Hadoop Distributed File System (HDFS)
- Programming model: MapReduce, Spark
Storage Infrastructure
Problem: node가 실패하면, 어떻게 데이터를 저장할 수 있을까?
Answer: 분산파일시스템(Distributed File System, DFS)
아무 시스템에 적용하지 않는다. 주로 (1) 대용량 데이터 (100GB ~ TB 급)이면서 (2) data update는 거의 일어나지 않고, (3) read/append는 자주 사용되는 환경에서 분산파일시스템이 적합하다.
※ 분산처리시스템과는 다르다.
Distributed File System (DFS)


Chunk server
- File을 연속적인 청크로 쪼갠다. (contiguous chunk)
- 일반적으로 chunk의 크기는 16MB-64MB
- 각 chunk는 복제되고, 다른 rack에 복사본을 저장한다.
Master node (Name node in HDFS)
- file이 어디에 저장되었는지에 대한 metadata를 저장한다.
- 하드웨어 failure에 훨씬 더 robust해야하고, cluster service를 실행한다.

MapReduce
맵리듀스는 아래 3가지 프로그래밍 디자인이 고려되었다.
- 쉬운 병렬 컴퓨팅 (easy parallel programming)
- 하드웨어 관리와 소프트웨어 실패는 보이지 않는다
- very-large-scale data를 쉽게 다룬다
MapReduce를 구현한 소프트웨어는 Hadoop, Spark, Flink 등이 있다. 구글이 처음 구현한 이름은 MapReduce 이다. (MapReduce:Simplified Data Processing on Large Clusters) (PageRank를 계산하기 위해 matrix-vector 곱셈이 필요했다)
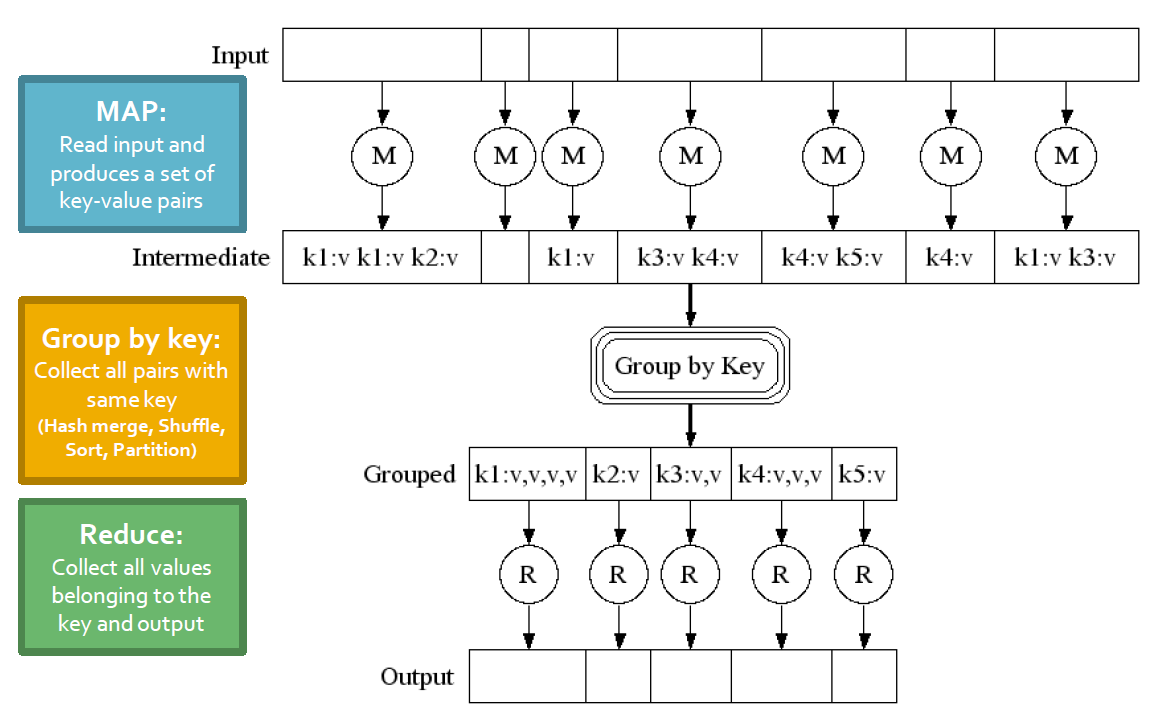
MapReduce는 크게 Map - Group by key - Reduce 이렇게 3단계로 이루어져있다.
- Map: user(혹은 프로그래머)가 작성한 Map function을 이용하여 (key, value) 를 반환한다.
- Group by key (Sort and Shuffle): system에서 (key, value) pair를 정렬하고 합쳐서 (key, list of values) pair를 반환한다.
- Reduce: user가 작성한 Reduce function을 적용하여 key, list of values를 얻는다.

Example: Word Counting
매우 큰 text 문서에서 단어의 빈도수를 구해보자.
실제로 web server log 파일을 분석하거나 statistical machine translation에서 자주 사용된다.

# key: document name
# value: text of the document
map(key, value):
for each word w in value:
emit(w, 1)
# key: a word
# values: an iterator over counts
reduce(key, values):
results = 0
for each count v in values:
result += v
emit(key, result)Datails of MapReduce Execution
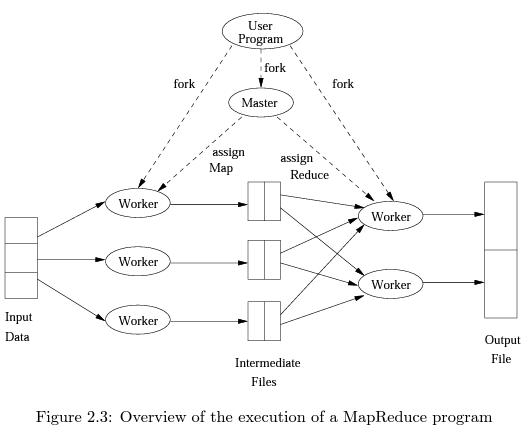
user program이 Master process와 몇개의 Worker process를 fork한다. 일반적으로 Map Worker와 Reduce Worker로 나뉜다. (하나의 Worker가 Map과 Reduce 둘 중 하나의 task만 담당한다.)
[Master controller]
Master는 Map, Reduce task를 생성한다. (task 개수는 user program으로 부터 결정). 생성된 task는 각각 Map/Reduce Worker process로 전달된다. 일반적으로 하나의 chunk에 하나의 Map을 할당하고, Reduce는 보다 적게 할당한다. (Reduce가 너무 많으면 itnermediate file이 너무 많아지는 문제가 생긴다.)
Map/Reduce task의 상태(idle, executing, completed)를 계속 추적한다. Worker process는 자신의 task가 끝나면 Master에 결과를 전달하고(report) 새로운 task를 받는다. (new task is scheduled by Master)
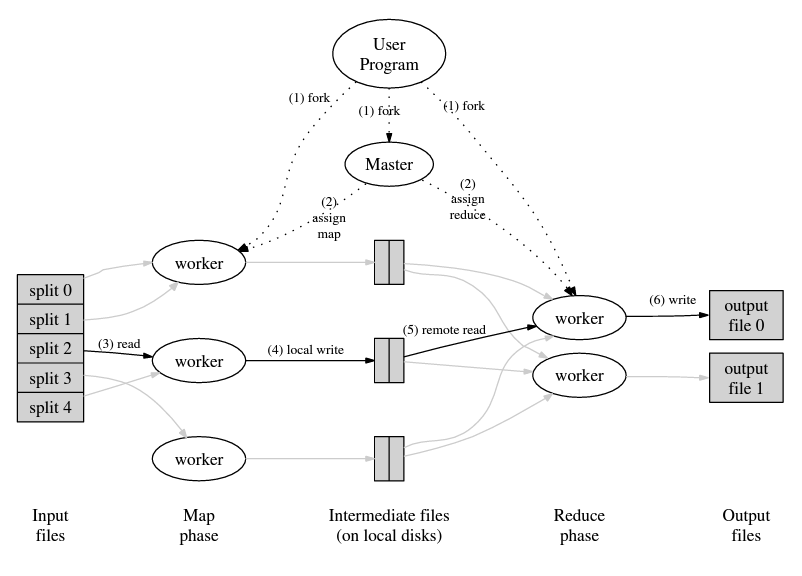
[Map]
Map task는 입력받은 파일의 (하나 이상의) chunk로 할당받고 user가 작성한 코드를 실행한다.
각 Reduce task에 해당하는 파일을 local disk에 만들고 Master에 이 파일의 위치, 크기, 도착지 Reduce task 등의 정보를 전달한다.
[Reduce]
Reduce task가 Master로부터 Worker process를 할당받을 때, (Reduce의) 입력이 되는 모든 파일이 주어진다.
user가 작성한 Reduce 코드를 실행하여 그 결과를 주위 DFS에 저장(write)한다.
Coping with Node Failures
Master failure
전체 MapReduce job을 재시작한다.
Map worker failure
Master로부터 failure를 감지. (주기적으로 ping을 통해 통신)
해당 Worker로 할당된 Map task는 (심지어 완료되었어도) 다시 재시작(redone)한다.
Reduce worker failure
in-progress task는 idle로 하고, Reduce task를 재시작한다.
How many Map/Reduce jobs?
$M$개의 Map task와 $R$개의 Reduce task가 있다고 하자.
일반적으로 다음과 같은 rule of thumb가 있다.
- $M$ > cluster에 있는 node 개수
- 하나의 chunk는 하나의 map에 매핑 (One DFS chunk per map)
- dynamic load balancing
- $R < M$: 결과는 $R$개의 파일로 뿌려질 것이기 때문
MapReduce Pipelining
map task >> machine 개수

Algorithm Using MapReduce
MapReduce는 모든 알고리즘에 사용되지 않는다. (예: online retail sales 기록)
그러나 online retail sales로부터 analytic query를 실행할 때는 MapReduce를 사용할 수 있다. (예: buying pattern)
원래 Google의 MapReduce의 목적은 PageRank를 빠르게 계산하기 위함이다. (original paper에서는 해당 표현을 찾을 수 없고, MMDS textbook에서 주장). MapReduce를 이용하여 행렬-벡터, 행렬-행렬 곱셈 연산을 병렬적으로 빠르게 계산할 수 있다.
MMDS 교과서에서는 행렬-벡터 곱셈, 행렬-행렬 곱셈, Relational-Algebra 연산(SQL에서 사용하는 연산 등)을 예시로 소개한다.
Matrix-Vector Multiplication by MapReduce
$M$이 $n \times n$ 행렬이고 $\mathbf{v}$는 길이가 $n$인 벡터라고 하자. 그리고 이 둘의 곱의 결과를 $\mathbf{x} = M \mathbf{v}$ 라 하자. (당연히 크기가 $n \times 1$ 이다.) 수학적으로 표현하면 다음과 같다.
\[ \mathbf{x}_i = \sum_{j=1}^{n}m_{ij} v_j \]
$n=100$이면 DFS 없이 그냥 local memory로 계산하면 된다. 그러나 Web page 규모를 생각해보면 local main memory로 계산이 불가능하다. 이제 MapReduce로 행렬-벡터 곱셈을 구현해보자.
$\mathbf{v}$가 main memory에 load될 수 있을 때는 Map/Reduce function은 다음과 같다.
| Map function | Reduce function |
| Input: $m_{ij}$ Output: (key, value)=($i,\ m_{ij}v_j$) |
Input: (key, list of values) = ($i,\ [m_{i1}v_1,\ m_{i2}v_2, \dots, m_{in}v_n]$) Output: ($i,\ \sum_{j} m_{ij}v_j$)=($i, x_i$) |
$M = \begin{bmatrix} 1 & 2 \\ 1 & 3 \end{bmatrix}$, $\mathbf{v} = \begin{bmatrix} 10 \\ 20 \end{bmatrix}$ 일 때, (index는 수학적 표현으로 1부터 시작)
Map function의 output은 ($1,\ 10$), ($1,\ 40$), ($2,\ 10$), ($2,\ 60$)이고
Group by key의 output은 ($1,\ [10,\ 40]$), ($2,\ [10,\ 60]$) 이고
Reduce function의 output은 ($1,\ 50$), ($2,\ 70$) 이다.
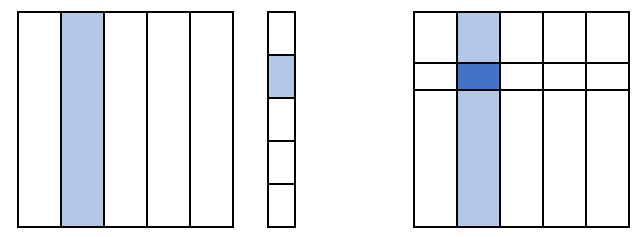
$\mathbf{v}$가 너무 커서 main memory에 load될 수 없을 때는 나누어서 생각한다.
$M$과 $\mathbf{v}$를 동일한 개수의 stripe로 나누어서, 각 stripe가 memory를 초과하지 않도록 stripe 개수를 조절한다.
그리고 각 stripe에서 위와 동일한 방식으로 행렬-벡터 곱셈을 MapReduce로 계산한다.
아래 그림은 5개의 stripe로 나눈 모습이다.
'스터디 > 데이터사이언스' 카테고리의 다른 글
| [CS246] Frequent Itemsets Mining & Association Rules (0) | 2023.09.11 |
|---|---|
| [CS246] Spark: Extends MapReduce (0) | 2023.09.09 |
| [Data Science] K-Nearest Neighbor (k-NN, Lazy Learning, k-최근접 이웃) (0) | 2023.06.10 |
| [Data Science] Mediator, Moderator (0) | 2023.05.15 |
| Dummy coding, Effect Coding (0) | 2023.05.15 |



