
pandas는 크게 3가지 Object로 구성되어있다. Index, Series, DataFrame
Index object
Series와 DataFrame은 index 객체를 포함하고있고, index를 바탕으로 데이터를 조작/변형할 수 있다.
Series는 1개의 index를, DataFrame은 2개의 index(row index, column index)를 갖고 있다.
Index는 immutable array이고 ordered set이다. multi-set이므로 repeated value를 가질 수 있다.
ind = pd.Index([2, 3, 5, 5, 11])
print(ind)
print(ind.size, ind.shape, ind.ndim, ind.dtype)
----- result -----
Int64Index([2, 3, 5, 5, 11], dtype='int64')
5 (5,) 1 int64
Index as immutable array
Index는 기본 파이썬의 list, numpy의 indexing, slicing이 가능하다. 그러나 immutable하기 때문에 값의 변형은 할 수 없다.
print(ind[0], ind[2], ind[-1]) # 2 5 11
print(ind[::2]) # Int64Index([2, 5, 11], dtype='int64')
ind[0] = 9 # TypeError: Index does not support mutable operationsIndex as ordered set
Index는 Python의 set과 동일한 연산을 할 수 있다. (e.g. union, intersection, difference, ...)
내부적으로 BST로 구현되어 ordered-set이다. 그리고 multiple entry가 허용되어 동일한 원소를 포함할 수 있다.
# Index as a set
ind1 = pd.Index([1, 3, 5, 7, 9])
ind2 = pd.Index([2, 3, 5, 7, 11])
print(ind1.union(ind2))
# Int64Index([1, 2, 3, 5, 7, 9, 11], dtype='int64')
print(ind1.intersection(ind2))
# Int64Index([3, 5, 7], dtype='int64')
print(ind1.difference(ind2))
# Int64Index([1, 9], dtype='int64')
print(ind1.symmetric_difference(ind2))
# Int64Index([1, 2, 9, 11], dtype='int64')Series object
Series 객체는 1차원 numpy array와 index가 결합된 형태와 거의 유사하다.
index는 default inddex일 경우 RangeIndex(start, stop, step)인 객체로 정의되며, named index로 사용할 수 있다.
value의 경우 1D numpy array이다.
data = pd.Series([0.25, 0.5, 0.75, 1.0])
print(data)
0 0.25
1 0.50
2 0.75
3 1.00
dtype: float64
print(data.values)
[0.25 0.5 0.75 1. ]
print(data.index)
RangeIndex(start=0, stop=4, step=1)위에서 print(data)의 왼쪽 [0, 1, 2, 3]이 index, 오른쪽 [0.25, 0.5, 0.75, 1.0]이 series의 value가 된다.
print(data[1])
0.5
print(data[1:3])
1 0.50
2 0.75
dtype: float64index 역시 named index로 정의할 수 있다.
data = pd.Series([0.25, 0.5, 0.75, 1.0],
index=['a', 'b', 'c', 'd'])
print(data)
a 0.25
b 0.50
c 0.75
d 1.00
dtype: float64
print(data['b']) # 0.5Series as a specialized dict
python의 dict로도 Series 객체를 생성할 수 있다. dict의 key, value는 각각 index, value로 매핑된다.
Series sclicing은 딕셔너리와 다르게 arrya-style을 지원한다.
population_dict = {
'Seoul': 9436836,
'Busan': 3320276,
'Incheon': 2964820,
'Daegu': 2365619,
'Daejeon': 1446749,
}
# create pandas Series using dict
population = pd.Series(population_dict)
print(population, "\n")
Seoul 9436836
Busan 3320276
Incheon 2964820
Daegu 2365619
Daejeon 1446749
dtype: int64
print(population['Busan']) # 3320276
print(population['Seoul': 'Incheon'])
Seoul 9436836
Busan 3320276
Incheon 2964820
dtype: int64DataFrame object
pandas를 사용하는 가장 큰 이유 아닐까 싶다. 대부분의 데이터는 테이블 형태로 저장되는데(엑셀과 Tableau를 이용하여 데이터를 보는 걸 보면 많이 사용된다) DataFrame은 이러한 테이블 데이터를 저장하고 표현하는데 적합하다.
values: numpy 2d-array 기반으로 구현
index: row index (ordered set)
columns: column index (ordered set)
column들이 각 Series에 mapping
population_dict = {
'California': 38332521,
'Texas': 26448193,
'New York': 19651127,
'Florida': 19552860,
'Illinois': 12882135
}
area_dict = {
'California': 423967,
'Texas': 695662,
'New York': 141297,
'Florida': 170312,
'Illinois': 149995
}
population = pd.Series(population_dict)
area = pd.Series(area_dict)
states = pd.DataFrame({
'population': population,
'area': area
})
states
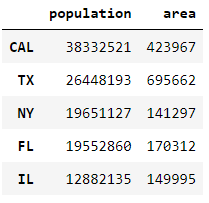
states2 = states.rename(index={
'California': 'CAL',
'Texas': 'TX',
'New York': 'NY',
'Florida': 'FL',
'Illinois': 'IL'
})
states2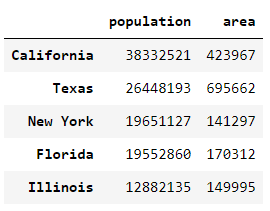
DataFrame의 column은 일종의 dict로 동작한다.
print(states['population'])
print('=====')
print(states['area'])
California 38332521
Texas 26448193
New York 19651127
Florida 19552860
Illinois 12882135
Name: population, dtype: int64
=====
California 423967
Texas 695662
New York 141297
Florida 170312
Illinois 149995
Name: area, dtype: int64list of dict로도 DataFrame을 만들 수 있다
data = [{'a': i, 'b': 2 * i} for i in range(5)]
print(data)
print(pd.DataFrame(data))
{'a': 0, 'b': 0}, {'a': 1, 'b': 2}, {'a': 2, 'b': 4}, {'a': 3, 'b': 6}, {'a': 4, 'b': 8}]
a b
0 0 0
1 1 2
2 2 4
3 3 6
4 4 8
missing value는 NaN으로 채워진다. NaN의 뜻은 Not a number의 약자다.
print(pd.DataFrame([{'a': 1, 'b': 2}, {'b': 3, 'c': 4}]))
a b c
0 1.0 2 NaN
1 NaN 3 4.0
2d-array로 DataFrame을 생성할 수 있다
pd.DataFrame(
np.random.rand(3, 2),
columns=['foo', 'bar'],
index=['alpha', 'bravo', 'charlie']
)
foo bar
alpha 0.144869 0.896950
bravo 0.580773 0.906061
charlie 0.760537 0.473426
'스터디 > 데이터사이언스' 카테고리의 다른 글
| [Data Science] 상관계수, Pearson, Spearman, Kendall (0) | 2023.03.17 |
|---|---|
| [Data Science] Basic Statistical Description of Data (0) | 2023.03.14 |
| [Data Science] Attribute Types (0) | 2023.03.09 |
| [pandas] [판다스] DataFrame 조작하기, MultiIndex (0) | 2023.02.15 |
| [NumPy] 넘파이 - 선형대수 (0) | 2023.02.14 |


