Vector Database
Why VectorDB?
전통적인 데이터베이스가 잘하던 것
전통적인 데이터베이스는의 대표적인 형태는 관계형 데이터베이스(RDBMS, RDB)이다.
숫자, 문자열, 날짜(datetime)처럼 명확한 구조를 가진 데이터(structured data, 정형 데이터)를 다루는데 강점이있다.
따라서 정확한 조건 기반 조회에 최적화되어있다고 볼 수 있다.
하지만 시스템입장이 아니라 사용자 입장에서 정확한 키워드를 알고 검색하지는 않는다.
딥러닝과 임베딩 시대의 검색 문제
현재 임베딩 모델은 주로 딥러닝 모델이며, 텍스트, 이미지, 오디오 등 다양한 데이터가 가능하다.
이는 기존 정형 데이터가 아니라 비정형 데이터를 주로 임베딩하여 활용한다.
현대 딥러닝 모델의 성과는 아주 성공적이므로, 적절한 임베딩 모델을 이용하여 임베딩을 이용해서 데이터분석도 한다.
RAG 역시 질의와 유사한 임베딩 벡터를 검색한 뒤, 그 벡터에 대응되는 문서나 청크를 가져와(retrieve), 이를 생성형 AI의 프롬프트에 추가(augmentation)하여 답변을 생성(generation)하는 구조이다.
※ 정형 데이터도 임베딩을 하는 경우도 있지만, 비정형 데이터의 저장과 검색에 초점을 맞춤.
데이터베이스, 벡터 인덱스, 그리고 벡터 데이터베이스
일반적인 RDB는 다음에 유리하다.
- 정형 데이터 저장
- 조건 기반 필터링
- 트랜잭션
- 조인 (JOIN)
- 정합성 관리
- 인덱스 기반 검색 (lookup)
벡터 인덱스는
벡터 데이터베이스는 벡터 인덱스를 포함하지만, 아래와 같은 기능도 제공한다.
- 벡터 저장
- 메타 데이터 저장
- 유사도 검색
- 필터 결합 검색
- 인덱스 관리
- 분산 처리
- API 제공
- 운영 편의 기능
벡터 DB의 주요 연산
RDB의 CRUD와 비슷하게 저장 및 변경, 조회, 인덱스 관리로 나눌 수 있다.
그게 Insert/Upsert, Delete, Search, Index Managing 이다
삽입: Insert / Upsert
파이프라인: 원본 데이터 수집 - 임베딩 모델로 벡터 생성 - 벡터와 메타데이터 저장 - 인덱스 반영
실제로는 insert보다는 upsert를 더 자주 사용한다.
동일한 ID가 있으면 update하고, 없으면 새로 insert하는 방식이다.
삭제: Delete
RDB에서는 row만 삭제하면되지만 (cascade 등) ANN인덱스에서는 내부 구조가 훨씬 복잡하다.
그래프 기반 인덱스에서는 노드 삭제가 전체 그래프 구조의 연결성에 영향을 주기 때문이다.
논리 삭제, 비활성화 마킹, 주기적인 compaction, 인덱스 rebuild 같은 전략을 사용할 수 있다.
단순히 SQL의 DELETE와는 다른 의미를 갖는다.
조회: Search / Query
Exact k-NN, Approxmimate Nearest Neighbor (ANN) 검색, 메타데이터 필터 결합 검색
그러나 Exact k-NN은 데이터가 커질수록 매우 느려지기 때문에 대부분 ANN 기반 검색을 한다.
이 주제는 중요해서 다른 섹션에서 다룬다.
인덱스 관리
데이터가 많아질수록 "어떻게 저장했는가"보다, "어떻게 탐색 가능하게 구성했는가"가 중요하다.
검색 latency, memory, recall 유지, build cost 통제 등이 목표가 된다.
Approximate Nearest Neighbor (ANN)
정확한 최근접 이웃 검색대신에, 거의 가까운 이웃 벡터를 찾는 것이다.
약간의 recall 손실보다 큰 검색 속도 향상이 더 중요하기 때문이다.
속도-정확도, 메모리-검색 품질, 빌딩 시간 - 조회 성능 이렇게 trade-off를 유의한다.
벡터 DB를 지원하는 회사, 제품별로 어떤 벡터 인덱스를 제공하는지 유의한다.
IVF (Inverted File)
벡터 공간을 여러 클러스터로 나누고, 질의 벡터(q)와 가까운 일부 클러스터만 탐색하는 방식이다.
벡터들을 $K$개의 centroid로 군집화하고, 각 벡터를 가장 가까운 centroid bucket에 넣는다.
그리고 질의 시, 가까운 centroid 몇 개 선택하고 그 안에서 탐색한다.
탐색 범위를 줄이는 방식으로 검색 속도를 향상시킨 아이디어다.
centroid 개수, probe 개수 등이 주요 파라미터이다.

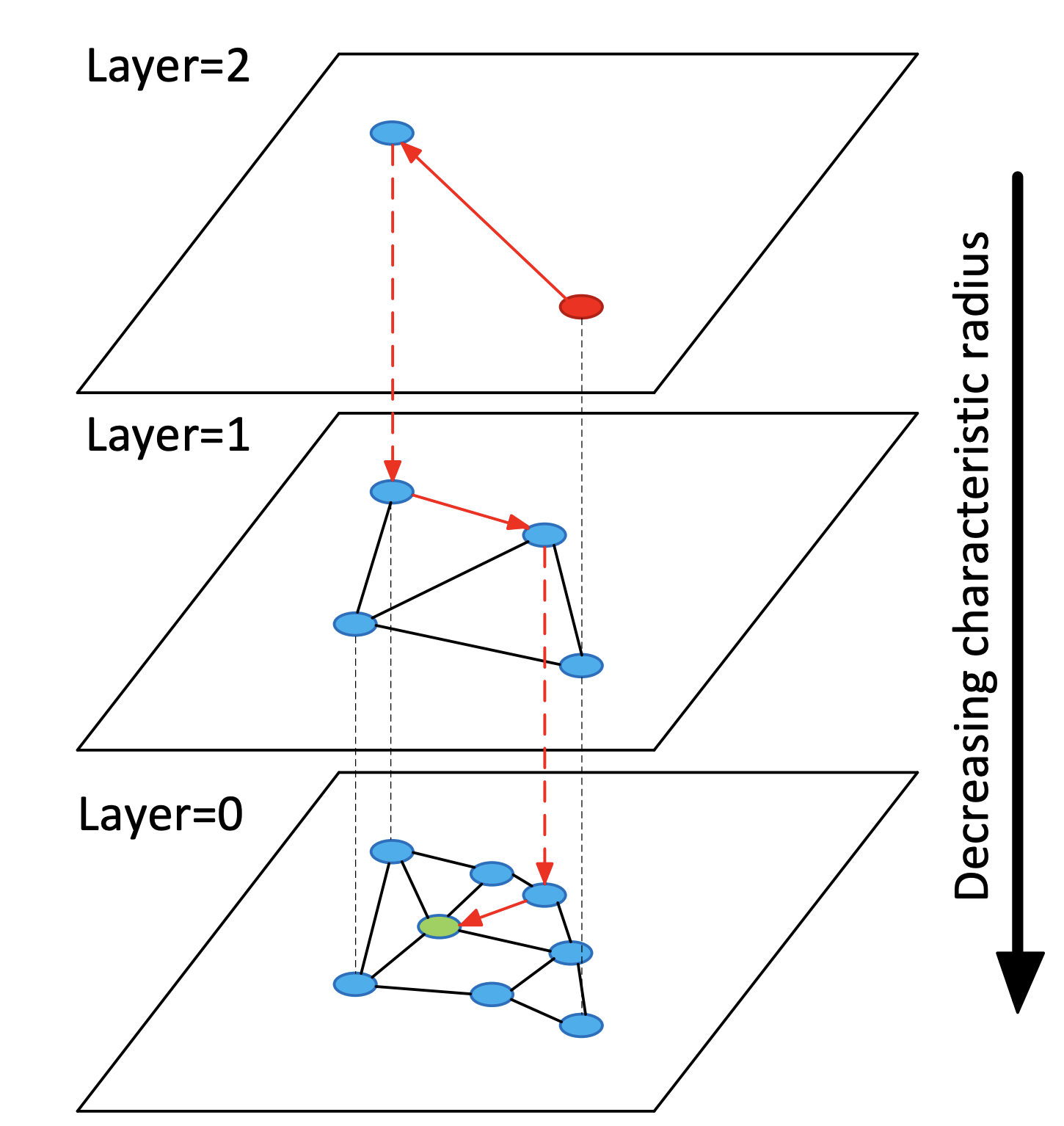
HNSW (Hierarchical Navigable Small World)
그래프 기반 인덱스다.
각 벡터를 노드로 보고, 가까운 노드끼리 연결하여 탐색할 그래프를 만든다.
질의 시에는 이 그래프의 계층마다 가까운 후보를 찾아간다.
계층 레벨이 내려갈 수록 탐색 범위(radius)도 점차 작아진다.
그래프로 구축하는 비용이 많이 들지만, 그만큼 recall 손실이 다른 방법보다 적은 것으로 보인다.
Product Quantization (PQ)
고차원 벡터를 여러 부분으로 나누과, 각 부분을 근사 표현하는 것이다.
원래의 벡터를 모두 저장하지 않아도 되기 때문에 저장 효율이 좋아진다.
그만큼 검색 정확도는 일부 떨어질 수 있지만, 서비스 레벨에선 고려대상이다.
PQ를 단독으로 이용하지 않고 IVF, HNSW 등에도 적용할 수 있다.
※ 벡터 DB의 성능에 영향을 미치는 것은 벡터 인덱스 뿐만 영향을 주지 않는다. 오히려 임베딩 모델, chunking 전략, distance metric, reranking 등이 훨씬 벡터 검색에 영향을 미친다.
Use Case
RAG
외부 문서나 외부 데이터를 임베딩하여 벡터 DB에 저장하고, 사용자 질문과 가까운 청크를 검색한 후 LLM에 전달하여 답변하도록 하는 방식이다. 모델의 파라미터 안에 없는 외부 지식(최신 지식 등)을 동적으로 로드하여 LLM의 답변의 환각을 줄일 수 있다.
추천 시스템
유저와 아이템을 같은 벡터 공간(임베딩 공간)에 두면, 비슷한 종류/성향의 유저와 상품을 찾을 수 있다.
텍스트 설명, 이미지, 행동 로그 등을 함께 반영할 수도 있다.
멀티모달 검색
이미지 임베딩, 텍스트 임베딩을 같은 공간에 두어 텍스트 질의로 이미지를 검색할 수 있다.
"검은색 신발"과 같은 것부터 "해변과 어울리는 사진"같은 텍스트도 가까운 이미지를 찾게 된다.
이를 확장하여 오디오 등도 가능하다.
AI Agent의 장기 기억
과거 대화, 작업 이력, 요약 정보 등을 벡터로 저장할 수 있다.
현재 작업과 의미적으로(semantic) 가까운 과거 작업들을 검색하여 컨텍스트로 활용할 수 있다.
'스터디 > 데이터사이언스' 카테고리의 다른 글
| 데이터분석 전문가 (ADP) 필기 합격 후기 (36회) (1) | 2026.03.07 |
|---|---|
| BM25: Information Retrieval (IR) Ranking Algorithm (정보검색 랭킹 알고리즘) (0) | 2026.02.27 |
| 이미지 명암 대비 개선 방법들 (Histogram Normalization, Histogram Equalization, CLAHE) (0) | 2025.12.28 |
| 빅데이터분석기사 실기 합격 후기 (10회) (3) | 2025.08.12 |
| 빅데이터분석기사 필기 합격 후기 (10회) (유관 전공) (0) | 2025.05.01 |



